-
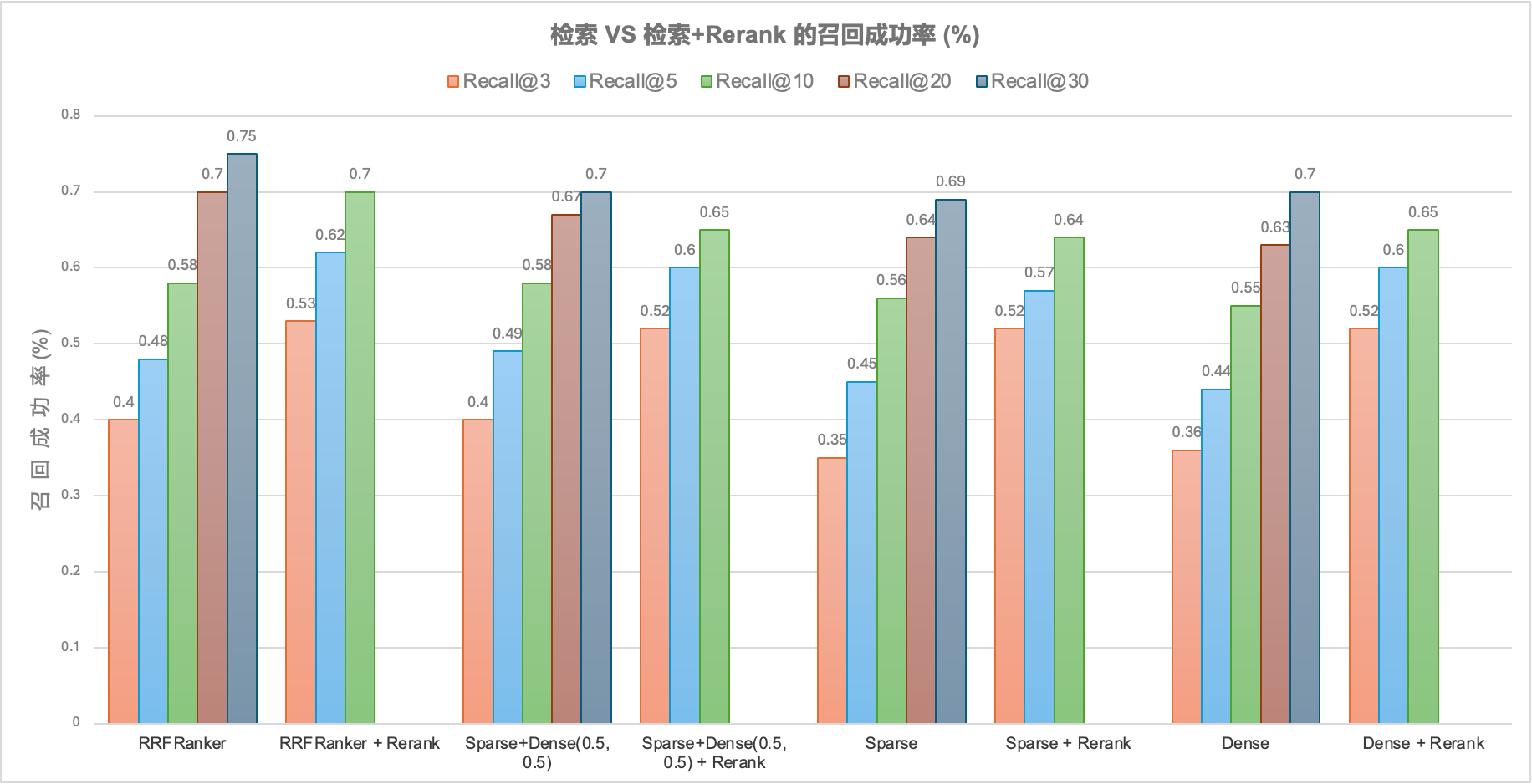
融合检索 & Rerank 在 RAG 中的效果评测
RAG 的基本原理 RAG 的工作流程主要分为两个阶段: Embedding 的缺点 Embedding 的具象化理解可以是,用一组高维数据来表达一段文本的核心内容。如果这段文本非常长,或者包含的内容非常多样化,那么固定维度的 embedding 是很难表达文本的全面内容的。因此:…
-
在企业内做平台,遇到强推的定制需求怎么办
如果你在企业里做平台,时间长了大概率会陷入这样一种状态: 你按照教科书般的架构设计,搭好了统一用户中心、标准化流程引擎、清晰的数据模型。上线时大家都很满意,觉得从此有了“统一平台”。 但很快,现实的需求开始一点点侵蚀这个理想架构。 销售部门来了:“我们最重要的客户,合同审批需要绕过三个部门,直接到副总那里。”财务部门来了:“所有超过五万的付款,必须增加一道线下邮件确认。”业务部门抱怨:“你们这个标准化流程太死板,我们实际的业务根本不是这样运行的。” 起初你还能守住边界,但架不住业务说“这个需求特别重要”“那个客户不能丢”。你开始妥协,在代码里加上一个又一个 if (specialCase) 的逻辑。 三年后回头看,平台上布满了各种补丁。新人不敢动老代码,老人不愿意碰复杂逻辑。每次需求评审会都变成拉扯——业务说你不懂实际业务,你说业务不懂技术代价。 这时候你会怀疑:是不是我的设计能力不行?还是说,这就是企业平台的宿命?…
-

AI编程的十字路口:资深开发者的兴奋、焦虑和故事
最近,关于“Vibe Engineering”的讨论在 hacker new 论坛引发了大量讨论和共鸣。在 700 多条评论中,开发者们分享了他们使用AI编码工具(如Claude Code、GPT等)的亲身体验,观点鲜明深刻,故事情感真挚。这已经不止于一场技术辩论,更是一场关于职业身份、工作乐趣和行业未来的思考了。所以我很想整理分享出来,以下是讨论内容的焦点。 是效率重要,还是可靠性重要? 1.…
-

从 Kimi Deep Research 看 Manus:我们真的需要一个通用 AI Agent 吗?
背景 近期,Kimi 上线了 “深度研究”(Deep Research)功能。我正好用它来解决一个实际的调研需求:AI Code Review 的工具调研。 为了更全面的视角,我同步对比测试了 Gemini…
-
Gemini Deep Research 是怎样工作的
Deep Research 是什么,为什么值得研究 当我们要在不熟悉的领域研究一个话题时,离不开搜索引擎。传统搜索费时费力,即便是新兴AI搜索(如Perplexity),也多止于浅层问答,难以进行扩展性搜索和深度调研。为此,Deep Research 应运而生:它能将模糊的研究任务拆解细化,在海量网络信息中主动搜索、筛选、乃至反思迭代,最终呈现一份条理清晰、内容详实的研究报告,而非零散观点。 Deep Research 的核心在于其自主思考的智能体(Agent)形态。它能主动规划路径,执行多步探索,并在过程中回顾调整。更关键的是,其背后的模型(如 Gemini)支持高达上百万…
-

当 Vibe Coding 遭遇 Vibe Hiring: Perplexity 的一场实习生招聘风波
这两天 Reddit 上一个吐槽 AI 招聘的帖子火了🔥 原帖的作者来自一家 AI 独角兽(后被指认是 Perplexity),作为招聘者在 Reddit…
-

Mac mini M4 vs. RTX 4090 vs. RTX 2080ti: 部署DeepSeek R1 的效果评测
导语 Apple 最新版 M4 芯片上市后,大家对在 Mac M4 上本地部署 LLM 热情不减。M…
-
深度解密 | DeepSeek R1 + 编程神器 Cline 是如何做到全自动化编程的?
【导语】当爆红的 DeepSeek R1 遇上编程界开挂神器 Cline (🏆OpenRouter工具榜TOP1),是1+1>2的超神组合,还是可怕的 Token 黑洞?实测 Debug 全过程,揭秘…
-
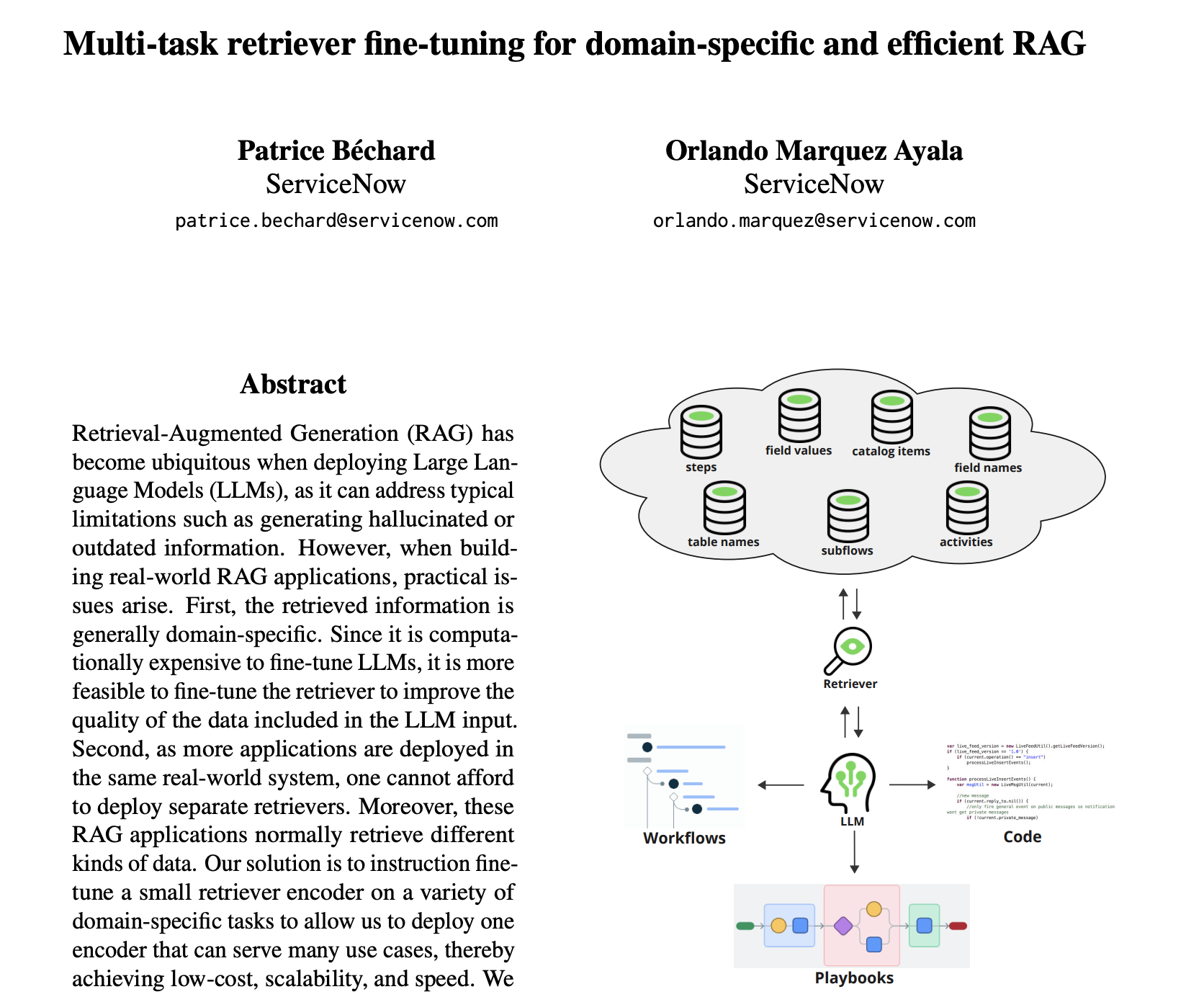
ServiceNow 通过精调 Embedding 模型提升 RAG 的准确性
ServiceNow 使用 RAG 技术解决什么问题 曾经简单的研究过 ServiceNow 这家公司的产品,了解到它主要是围绕 ITSM / 低代码领域做企业流程。…
-

Your Daily LLM & RAG Research Digest
Introduction The rise of Large Language Models (LLMs), particularly in…