RAG 的基本原理
RAG 的工作流程主要分为两个阶段:
- 检索阶段:利用查询(例如用户问题)的嵌入向量(embedding),从一个大型文档库中检索相关文档。这一步通常由一种高效的相似度搜索算法(如基于 FAISS 的向量检索)执行。
- 生成阶段:将检索到的相关文档与原始查询一同输入到生成模型中,以生成更精确和相关的回答。生成模型可以是如 GPT-3 这样的预训练语言模型。
Embedding 的缺点
Embedding 的具象化理解可以是,用一组高维数据来表达一段文本的核心内容。如果这段文本非常长,或者包含的内容非常多样化,那么固定维度的 embedding 是很难表达文本的全面内容的。因此:
- 用于 embedding 的文本长度不能太长。例如 OpenAI 官方文档里,一个文本 chunk 长度推荐 1000 token
- 如果文本太长,那么计算文本和用户问题的相似度分数的区分度很低
- embedding 对 keyword 式的用户 query 效果并不比传统关键词搜索能力强
融合检索和 Rerank
单纯使用 embedding 向量检索,在真实业务场景下的召回成功率很低。 常见的优化方案有:
- Hybrid retrieval:融合 embedding 和 keyword 检索等方式,并综合加权排序。融合召回可以充分发挥 embedding 和 keyword 检索的优点。
- Rerank:使用 Rerank 模型(或者 LLM api)对检索结果重排序,再取 Top N。Rerank 可以充分利用更强大模型的语义理解能力,弥补 embedding 和 keyword 检索的不足。
bge-m3 模型
bge-m3 模型自身支持了三种检索模式:Dense、Sparse、Multi-vector。官方介绍如下:
https://huggingface.co/BAAI/bge-m3
- Dense retrieval: map the text into a single embedding, e.g., DPR, BGE-v1.5
- Sparse retrieval (lexical matching): a vector of size equal to the vocabulary, with the majority of positions set to zero, calculating a weight only for tokens present in the text. e.g., BM25, unicoil, and splade
- Multi-vector retrieval: use multiple vectors to represent a text, e.g., ColBERT.
虽然官方提供了三种检索方式的代码 demo,但在真实场景下,embedding 向量需要存储在向量数据库,而检索计算能力必须由向量数据库支持。幸运的是,Milvus 向量数据库已经支持了 dense + sparse 混合检索方式 ,并支持双路加权排序。
评测方案设计
文档数据
我以一个真实业务场景下的真实文档和真实用户问答数据,来评测 Dense、Sparse、Hybrid 检索及叠加 Rerank 后的召回率。不评测生成阶段的 LLM 回答正确性。
| 知识库文档数目 | 评测问题数目 | 文档平均长度(字符数) | 文档最大长度(字符数) | 文档最小长度(字符数) |
| 1300 | 230 | 2000 | 8000 | 200 |
评测技术选择
- 所有文档不分 chunk。出于考虑简化评测脚本,以及考虑到 bge-m3 支持 8k token
- embedding 模型使用 bge-m3。因为它支持三种向量模式
- 重排序模型使用 bge-rerank-v2-m3
- 向量数据库使用 milvus。因为 milvus 官方支持 Dense、Sparse 多向量的存储和检索
评测目标
- 评测 Sparse、Dense、Sparse+Dense 三种检索方式不使用 rerank 时,在 Recall 3、5、10、20、30 条件下的召回成功率 hit rate
- 评测 Sparse、Dense、Sparse+Dense 三种检索方式叠加使用 rerank 时,在 Recall 3、5、10、20、30 条件下的召回成功率 hit rate
评测结果
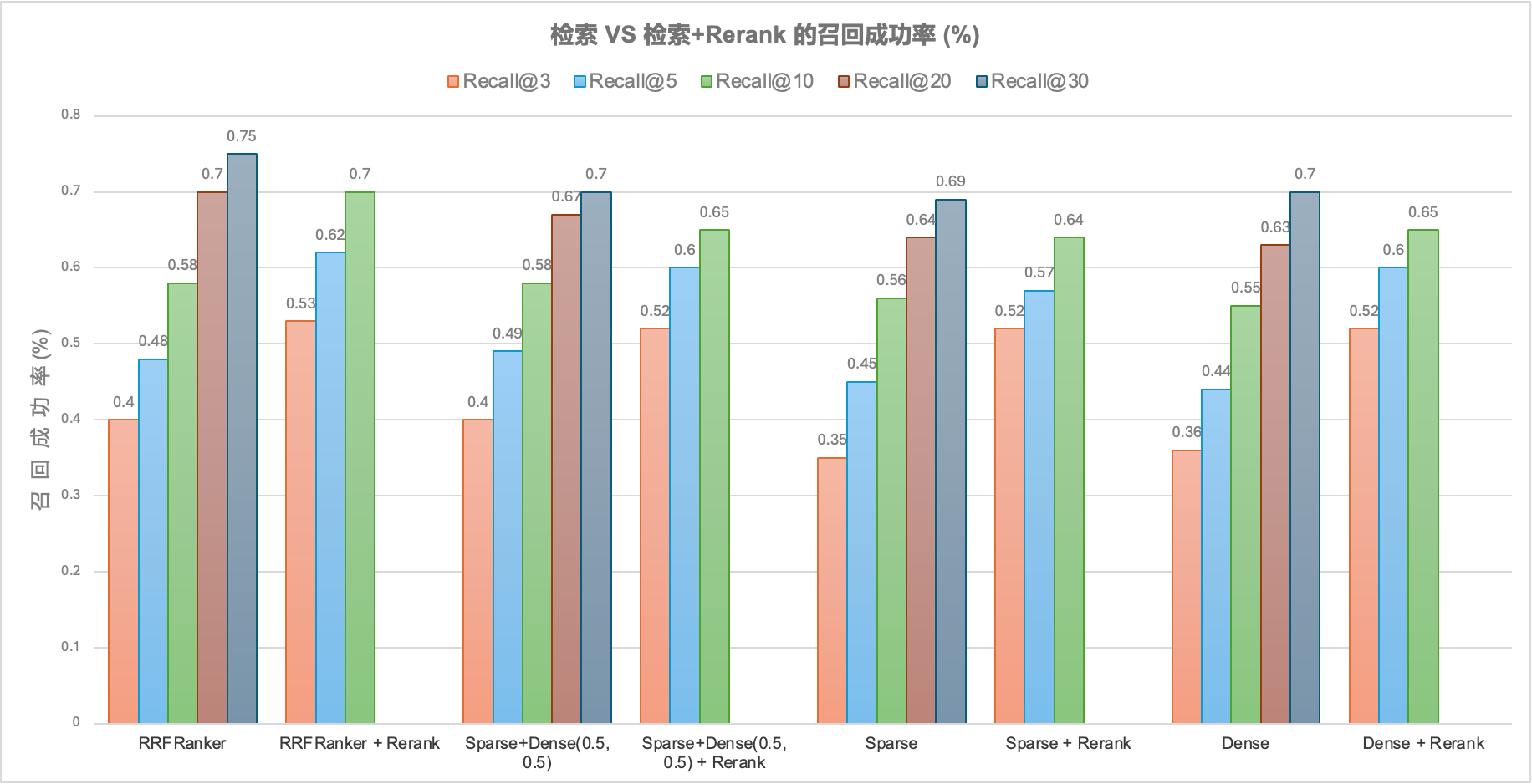
结果解读
- 召回成功率随着 Recal@N(召回文档数)的增加而显著提高,直到 N 达到一定量级时成功率接近平稳
- Rerank 对所有检索方案的最终成功率都有提升,提升幅度在 10%~15%
- 融合检索方案比单独的 Sparse 检索或 Dense 的成功率高,但并不明显
- 融合检索方案 RRF 算法和 Sparse + Dense 简单算法,召回成功率基本无差别
结论
- 对最终召回成功率提升最大的是提高 Recall@N 的数量。但这对 LLM 的 Context Length 和 In-Context learning 要求在提高
- Rerank 对检索结果的提升是直接的、确定的(10%~15%),但还是不够理想。对具体某个 query 案例,rerank 小概率会降低召回成功率
- 融合检索比单纯的 Sparse 或 Dense 检索都好,但优势不显著。可能需要针对不同 query 采用不同的融合排序的权重
- RAG 方案最终拼的还是检索能力。对 LLM 来说是 garbage in garbage out。是否是 garbage,取决于检索
融合召回加权排序算法 RRF,可以参考 这篇文档
Leave a Reply