
标题
AGRAME: Any-Granularity Ranking with Multi-Vector Embeddings
总结
本研究引入了AGRAME(Any-Granularity Ranking with Multi-Vector Embeddings),一种利用多向量嵌入进行任意粒度排名的方法,旨在通过编码级别的灵活性,实现从全文到句子甚至是命题层面的排名。
摘要
AGRAME是一个针对不同粒度排名的方法,它通过在单一的编码级别上使用多向量嵌入技术,能够在更细的粒度上进行排名,如句子级别或命题级别。研究团队包括来自伊利诺伊大学厄巴纳-香槟分校、苹果公司和Adobe公司的研究人员。他们提出了一种多粒度对比损失训练方法,用于提高基于ColBERTv2的多向量模型在更细粒度的排名任务中的性能。实验结果表明,AGRAME在自然问题解答、开放领域问题答erme、跨领域问题答erme以及命题级别的引用添加等多个任务中都表现出色,显著提高了在不同粒度上的排名性能。此外,研究还提出了PROPCITE方法,用于在生成的文本中添加引用,该方法通过使用命题作为查询来选择相关的上下文进行引用,在生成的文本中添加引用,并在检索增强的生成中表现出色。

观点
- 多向量嵌入的优势: 与单向量方法相比,多向量方法能够更好地进行细粒度的排名,因为它们可以利用词级别的嵌入来捕捉更细致的信息。
- 编码级别的灵活性: AGRAME能够在单一的编码级别上,通过使用不同的查询标记来实现不同粒度的排名,无需为每个所需的粒度级别创建单独的密集索引。
- 多粒度对比损失的效果: 通过引入多粒度对比损失,研究者提高了模型在句子级别和命题级别的排名能力,同时保持了段落级别的性能。
- 命题级别排名的实际应用: 研究展示了在生成文本中添加引用的任务中,通过使用命题作为查询来进行精细的属性添加,可以有效地提高引用的质量。
- 跨领域和多领域的泛化能力: AGRAME在多个不同领域的数据集上都展现了良好的性能,表明其跨领域和多领域的泛化能力。
- 与现有方法的比较: 实验结果显示,AGRAME在多个任务中都优于现有的单向量方法和其他基线方法,尤其是在命题级别的引用添加任务中。
Why
- Multi-vector embedding 可以获得更细粒度的语义信息
- 观测到,基于token-level 的embedding可以促进不同子部分的判别评分
贡献
- 任意粒度排名: 本文提出了 AGRAME 方法,能够在单一的编码级别上进行任意粒度的文本排名,包括句子级别和命题级别,而不需要为每个粒度级别创建专门的索引。
- 多粒度对比损失: 研究引入了一种新的多粒度对比损失训练策略,这种策略能够在训练过程中提供额外的句子级别的排名信号,从而提高了模型在更细粒度的排名任务中的性能。
- 命题级别的排名:基于 AGRaME 的命题级别的排名,超越现有 SOTA 模型。
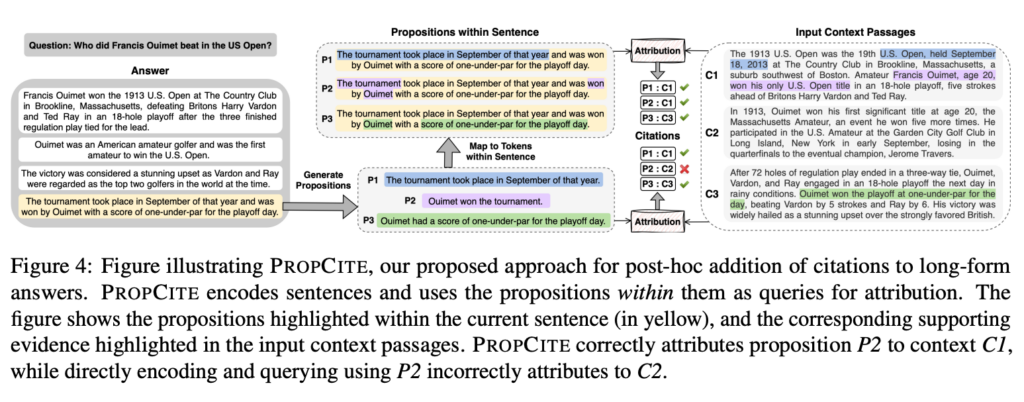
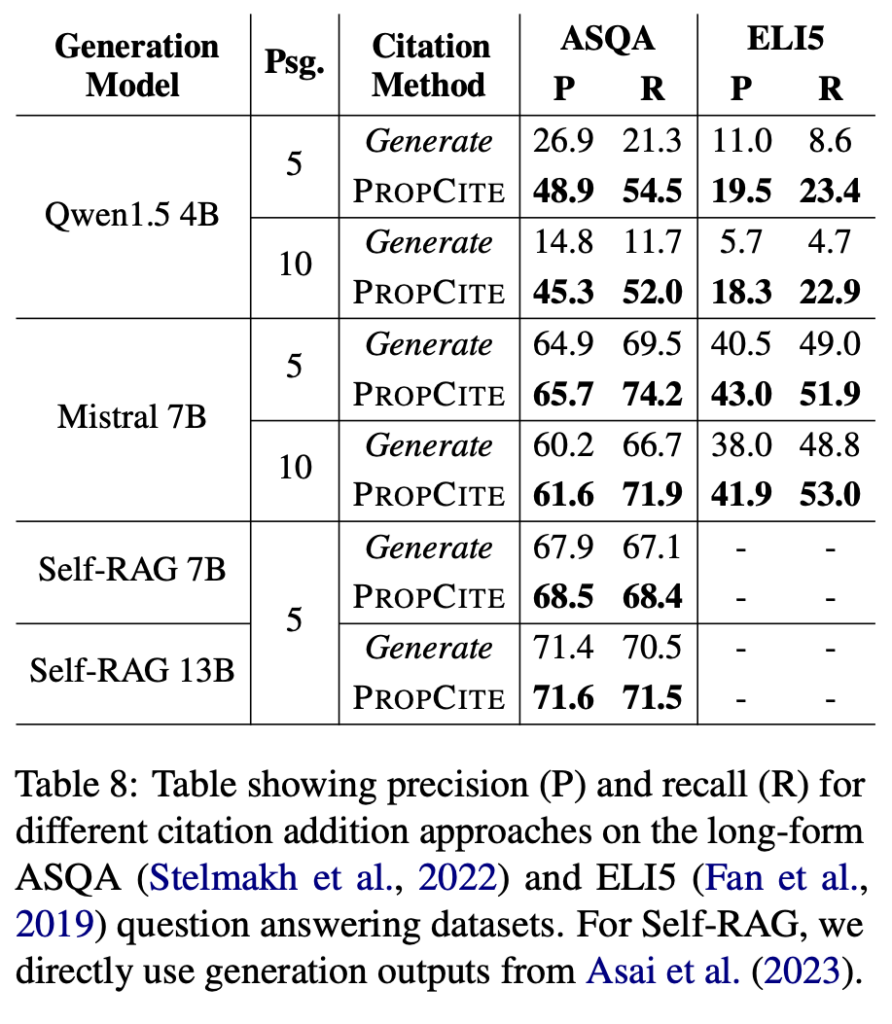
- 命题级别的引用添加: 本文提出了 PROPCITE 方法,它是一个后处理的引用添加方法,能够有效地使用命题作为查询来从输入的上下文中选择相关的引用,并将其添加到生成的文本中,这在检索增强的生成中表现出色。
假设验证
现有 ColBERTv2 模型在编码粒度的缺点,评测数据和示例
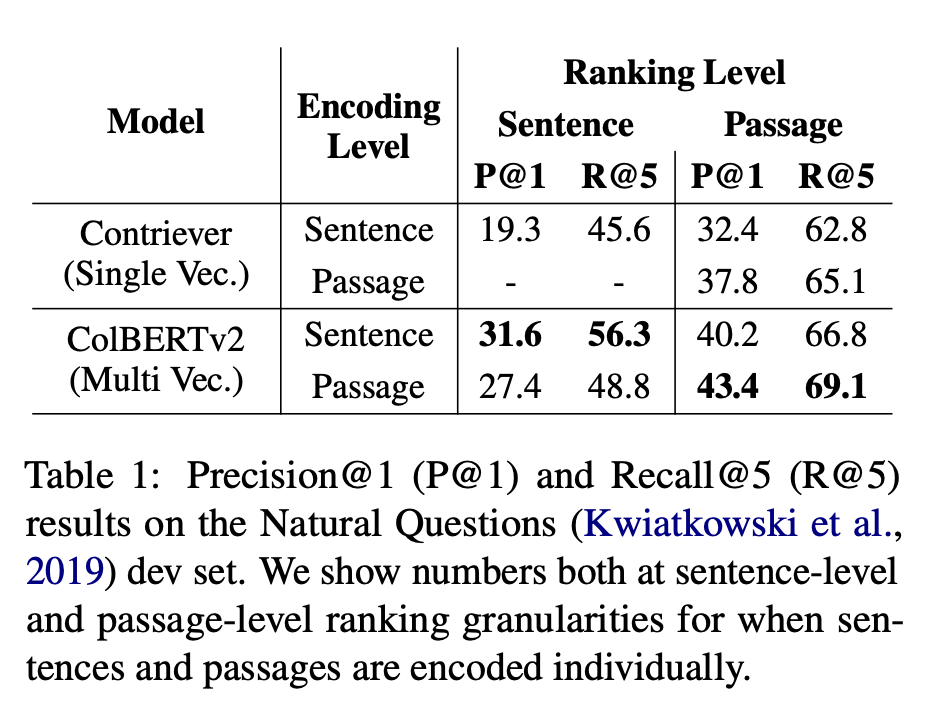
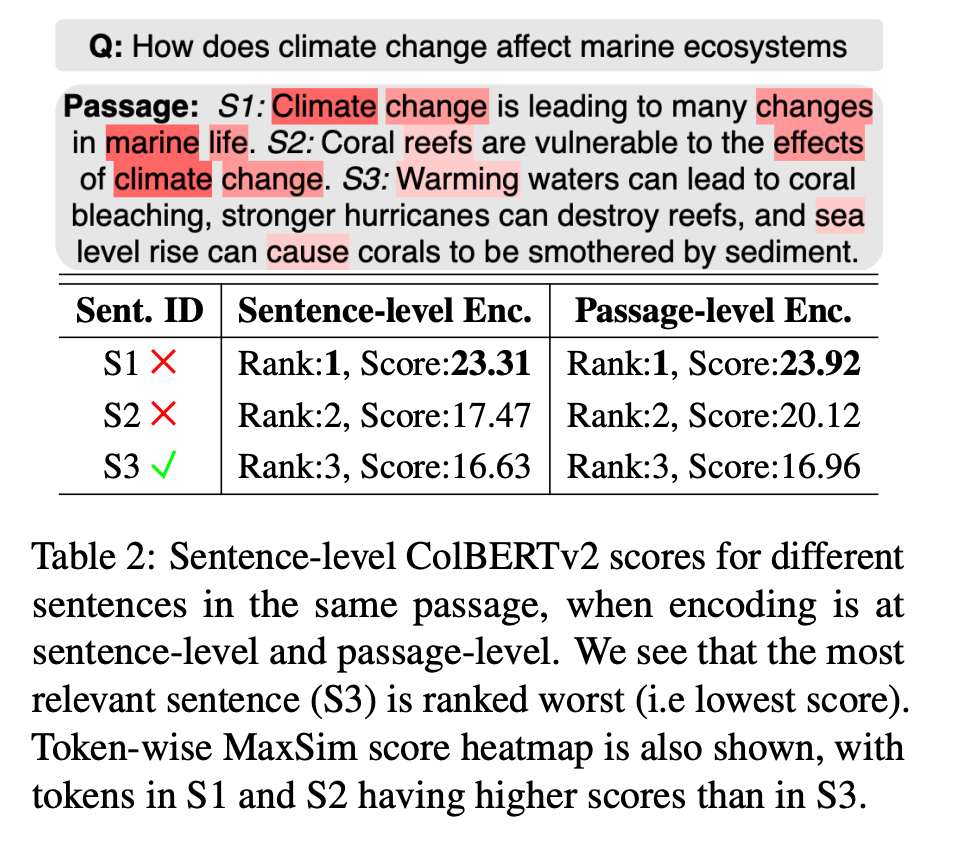
模型效果评测
多种数据集下的排序效果对比
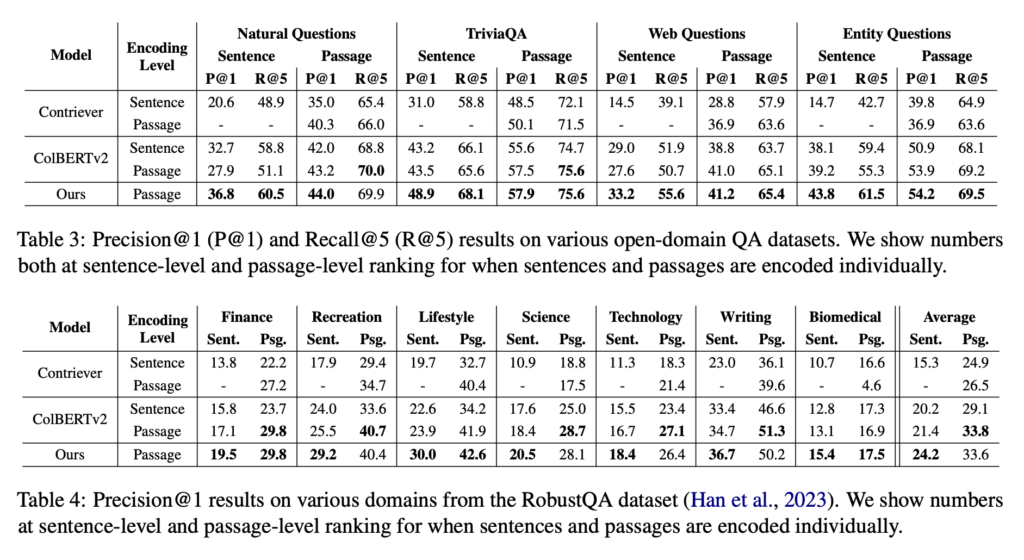
多模型对比
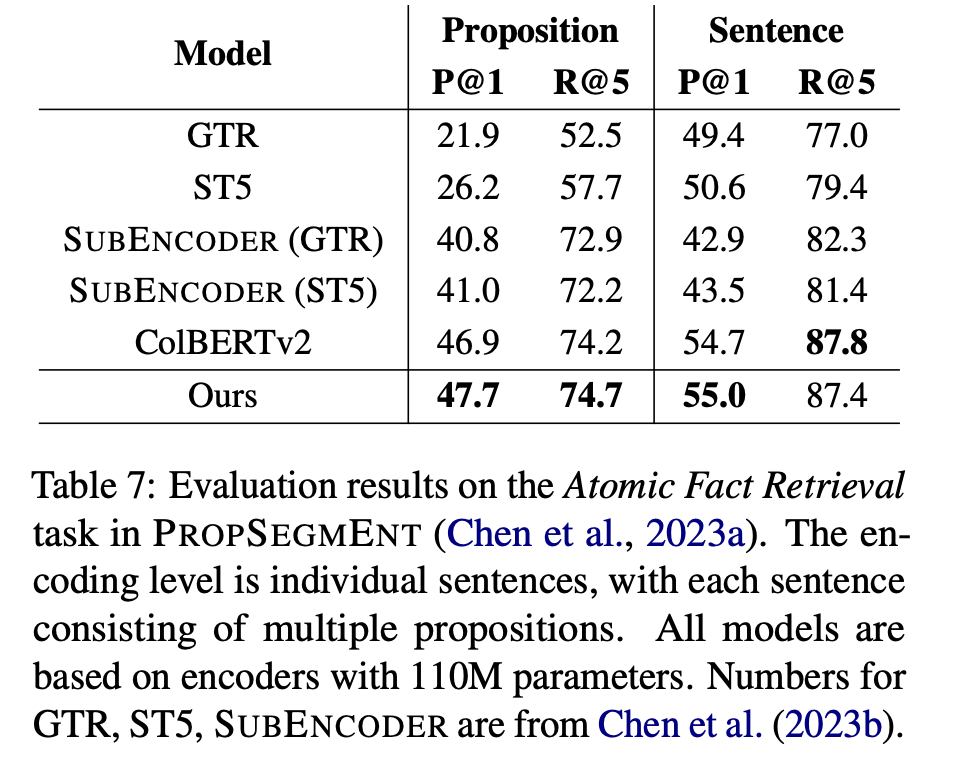
观点归因效果
Leave a Reply