对 Coze 上的 bot 的使用量数据有兴趣,想爬取下来分析热门 bot。虽然之前没做过这类爬虫,但好在有 ChatGPT,直接提问,多提几次,就能写出可用的爬虫了
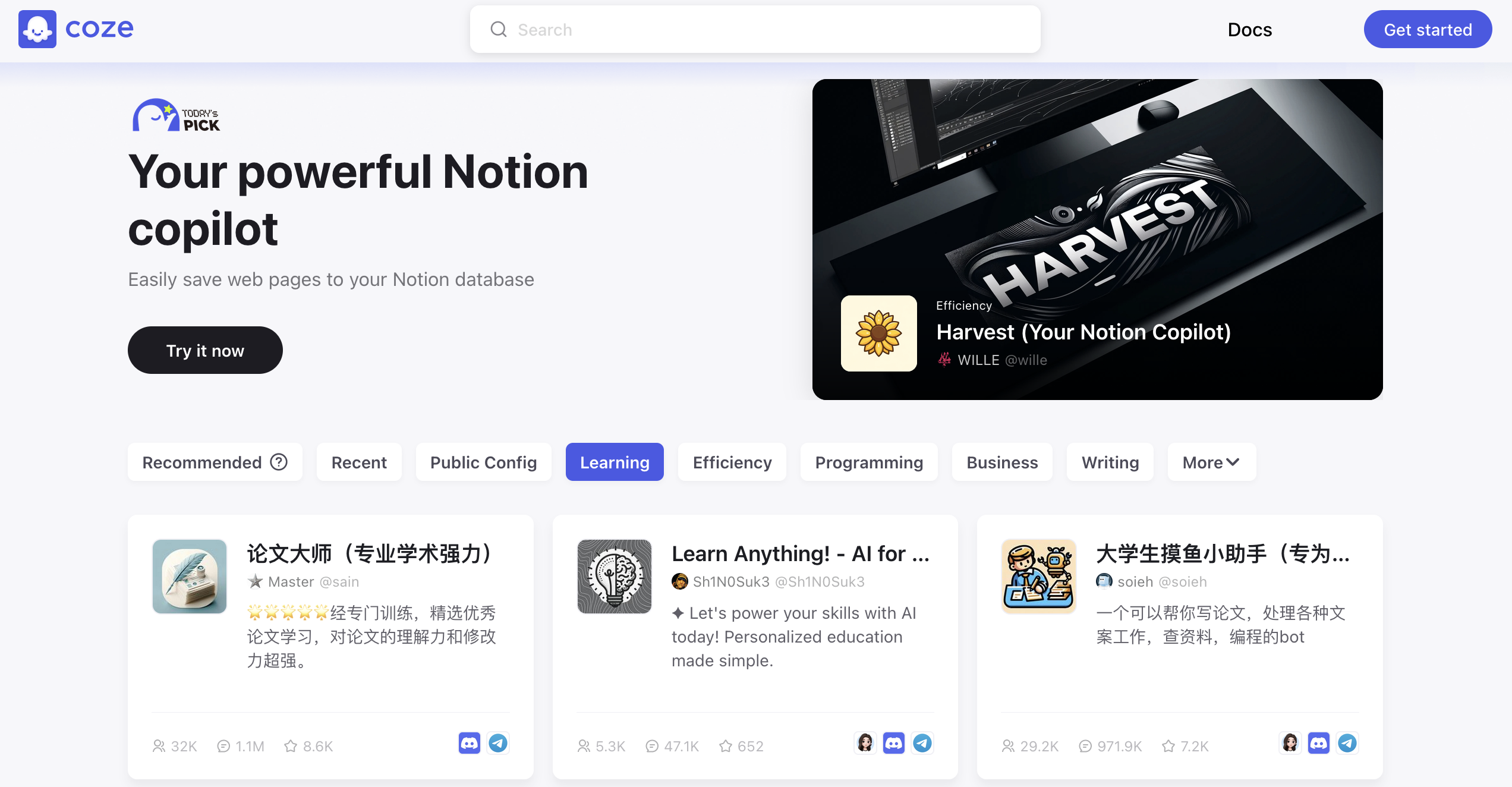
Coze bot store 网页结构
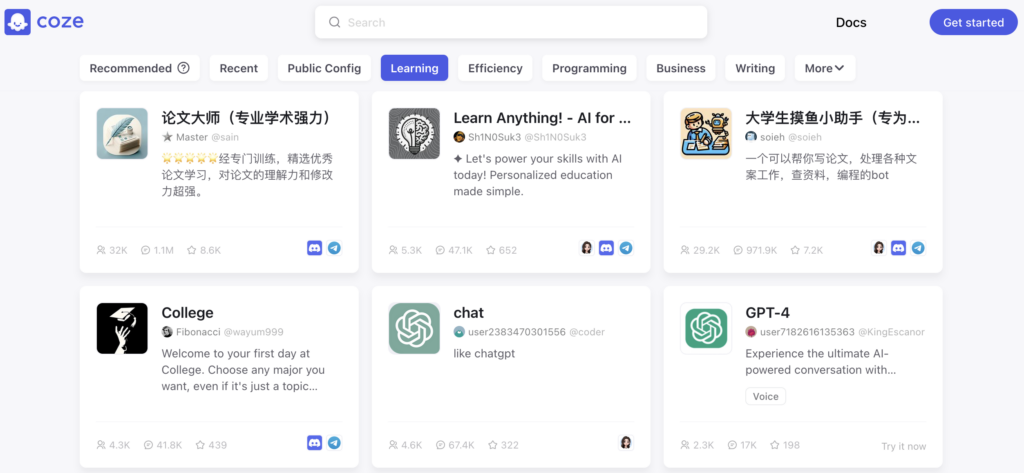
Coze 首页 就是 bot 列表,按 10 个类别组织。初始 bot 列表是 24 个 bot 卡片,bot 卡片已经有使用量数据了。页面底部的 ’Load more‘ 按钮触发滚动加载 bot 卡片
方案 Selenium
直接问 Gemini-1.5-Flash 如何模拟用户的翻页操作,Gemini 就推荐了 Selenium、Playwright 2 个工具
有很多浏览器模拟工具可以支持获取 API 返回内容,它们通常被称为 “Web 自动化工具” 或 “浏览器驱动工具”。以下是几个常用的工具:
1. Selenium:
- 功能强大: Selenium 是最受欢迎的 Web 自动化工具之一,支持多种浏览器,可以模拟用户操作,包括访问网页、填写表单、点击按钮等。
- 获取 API 返回内容: Selenium 可以通过
requests库或内置的get方法获取 API 返回内容,并解析 JSON 或 XML 数据。- 语言支持: 支持 Python、Java、C#、JavaScript 等多种编程语言。
2. Playwright:
- 现代化工具: Playwright 是一个相对较新的工具,由微软开发,支持 Chrome、Firefox、Safari 和 Edge 等浏览器。
- API 驱动: Playwright 提供简洁的 API,方便编写自动化脚本。
- 异步操作: Playwright 支持异步操作,可以提高爬取效率。
主要步骤
初始化 selenium 并加载初始网页
初始化一个 Chrome driver,加载第一个页面,由于加载需要一定时间,等待页面加载完毕
# Set up the Chrome driver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# Load the webpage
url = 'https://www.coze.com/?cate_type=publish_mode&cate_value=1'
driver.get(url)
wait = WebDriverWait(driver, 10)定位页面内容
由于 bot 卡片的 css class 是页面唯一的 aLnriRC1g8QLH0wzcyzQ,直接使用 CLASS_NAME 来定位卡片元素
driver.find_elements(By.CLASS_NAME, 'aLnriRC1g8QLH0wzcyzQ')在卡片内部按照 XPATH 绝对路径来定位 bot 名称、统计数据等其他信息。
注意,这个定位方式与页面设计有关,如果失效,需要分析页面
# bot 名称:
find_element(By.XPATH, './/div[1]/div[2]/span')
# bot 统计数据:
find_element(By.XPATH, './/div[3]/div[1]')定位加载按钮
因为 Load more 按钮 ’似乎‘ 没有唯一的 class name,所以使用它的所有 class name 组合定位
注意,这个定位方式与页面设计有关,如果失效,需要分析页面
load_more_button = wait.until(
EC.element_to_be_clickable(
(
By.CSS_SELECTOR,
"button.semi-button.semi-button-primary.semi-button-borderless.Vqs8pu0RTKoOl2fVHiq6.yJDwteqjbdkspQ0V7XOl"
)
)
)完整代码
完整代码如下
# -*- coding: utf8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up the Chrome driver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# Load the webpage
url = 'https://www.coze.com/?cate_type=publish_mode&cate_value=1'
driver.get(url)
wait = WebDriverWait(driver, 10)
while True:
# Firstly, check `Load more` button exists to ensure the page are rendered
# 这里使用 Load more 按钮的完整 css class 来定位
load_more_button = wait.until(
EC.element_to_be_clickable(
(
By.CSS_SELECTOR,
"button.semi-button.semi-button-primary.semi-button-borderless.Vqs8pu0RTKoOl2fVHiq6.yJDwteqjbdkspQ0V7XOl"
)
)
)
# Get robot cards in current page
# bot 卡片的 css class 是 aLnriRC1g8QLH0wzcyzQ
content = driver.find_elements(By.CLASS_NAME, 'aLnriRC1g8QLH0wzcyzQ')
for card in content:
try:
# 按照 bot 卡片中的 html 元素来绝对定位名称、作者、统计数据、描述等信息
# 注意:这个定位可能随着 Coze 网页改版而变化,需要及时调整
print(json.dumps(
{
"name": card.find_element(
By.XPATH,
'.//div[1]/div[2]/span',
).text,
"author": card.find_element(
By.XPATH,
'.//div[1]/div[2]/div/span',
).text,
"stats": card.find_element(
By.XPATH,
'.//div[3]/div[1]',
).text.replace("\n", ' | '),
"description": card.find_element(
By.XPATH,
'.//div[1]/div[2]/p',
).text,
},
ensure_ascii=False,
))
except:
print("Parse element error")
sleep_duration = random.uniform(1, 3)
time.sleep(sleep_duration)
if load_more_button:
print("Clear current cards, load more")
# 这里把当前页面的 bot 卡片删除,避免 Load more 后页面变长导致卡顿问题
driver.execute_script("document.querySelectorAll('.aLnriRC1g8QLH0wzcyzQ').forEach(el => el.remove());")
time.sleep(2)
# 点击 Load more 按钮加载更多 bot 卡片
driver.execute_script("arguments[0].click();", load_more_button)
time.sleep(1)
else:
print("No more button, work done")
break
申明:代码仅用于学习研究,请尊重网站知识产权
Leave a Reply