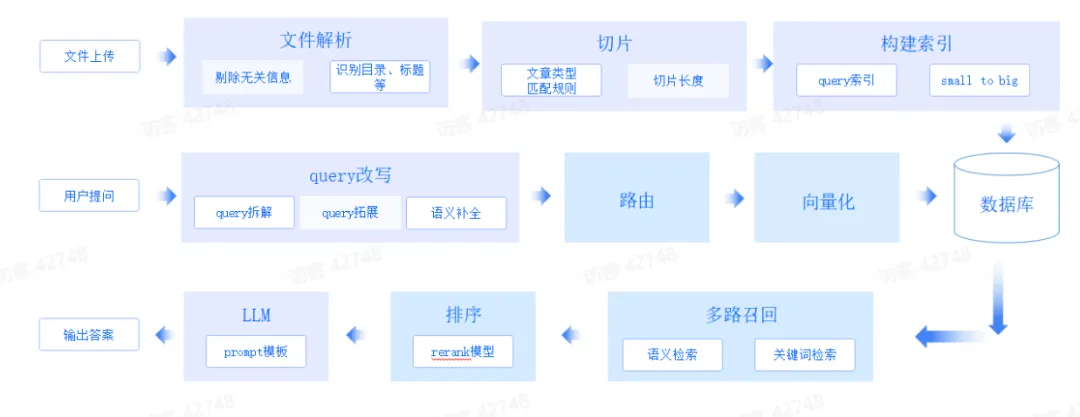
产品方案
知识运营层面的产品特性包括:知识类型管理、切片管理、索引管理、数据运营
知识问答过程的产品特性包括:历史消息、输入提示、原文索引、图文混排、原文查看
产品目标用户分类:个人使用、企业对内赋能、企业 toC 提供服务
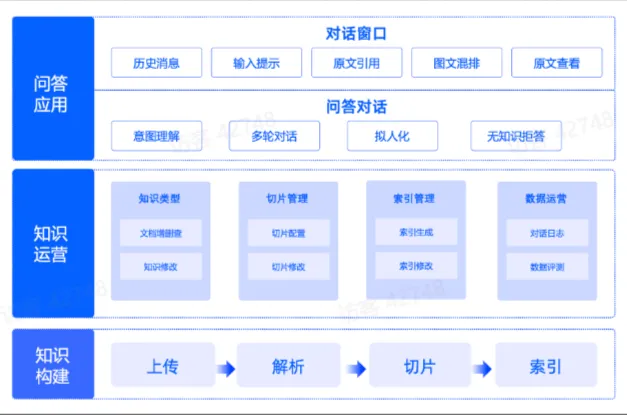
技术全景图
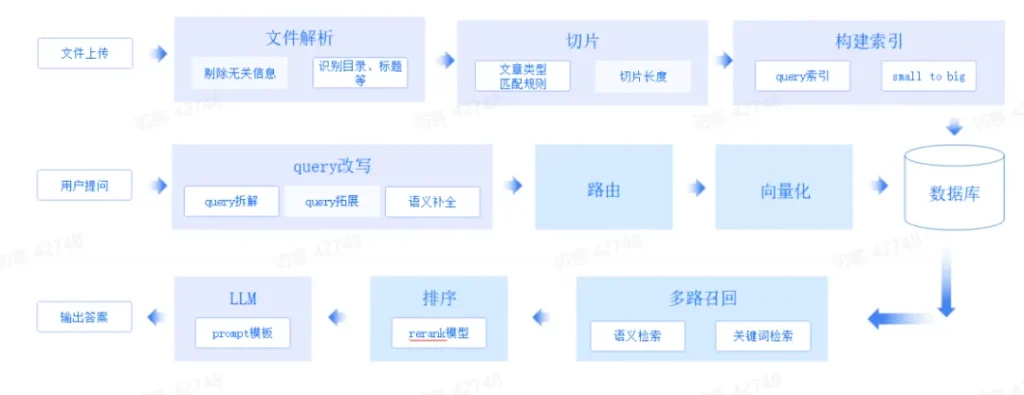
RAG技术挑战和方案
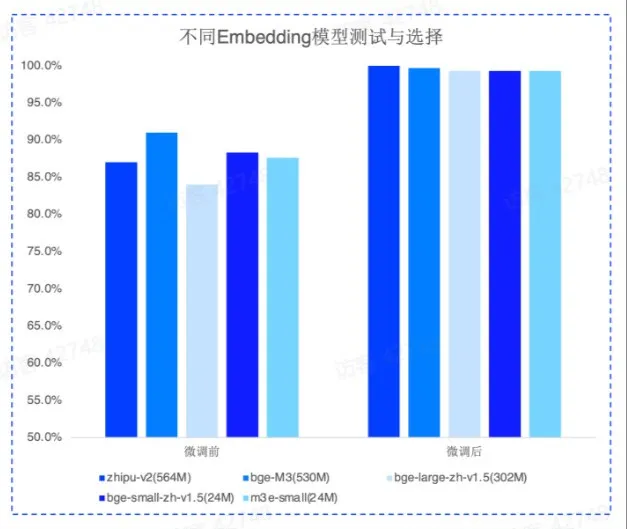
Embedding
- 切片问题:传统按长度切片方法效果不佳,因为政策内容知识密度高,每句话都可能包含答案,且条款间关联性强,需要连续多个条款才能完整回答问题。
- Embedding 微调:通用 Embedding 模型不足以应对用户口语化严重的问题,需要针对具体业务场景进行微调,以过滤无关信息并提高准确度。
针对前者,我们采用文章结构切片以及 small to big 的索引策略可以很好地解决。针对后者,则需要对 Embedding 模型进行微调。我们有四种不同的构造数据的方案,在实践中都有不错的表现:
- Query vs Original:简单高效,数据结构是直接使用用户 query 召回知识库片段;
- Query vs Query:便于维护,即使用用户的 query 召回 query,冷启动的时候可以利用模型自动化从对应的知识片段中抽取 query;
- Query vs Summary:使用 query 召回知识片段的摘要,构建摘要和知识片段之间的映射关系;
- F-Answer vs Original:根据用户 query 生成 fake answer 去召回知识片段。
经过微调后的 Embedding 模型在召回上会有大幅地提升。top 5 召回达到 100%,而且不同 Embedding 模型微调后的召回差异在 1 个点之内,模型的参数规模影响极小。
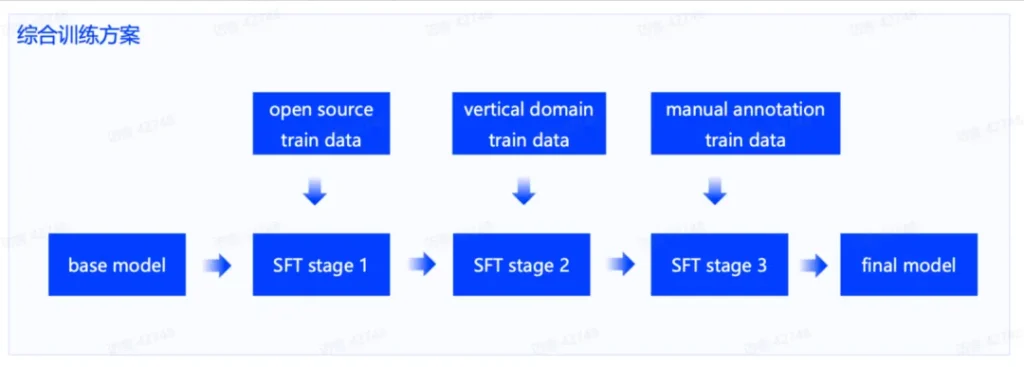
SFT&DPO
另外一个挑战是答案生成。在生成环节中,我们面临以下数据挑战:
- 数据标注难度大:业务人员虽然知道正确答案,但难以标注出满足一致性和多样性要求的模型微调数据。因此,我们需要在获取基础答案后,通过模型润色改写答案或增加 COT 的语言逻辑,以提高数据的多样性和一致性。
- 问答种类多样:业务需要模型能够正确回答、拒答不相关问题和反问以获取完整信息。这要求我们通过构造特定的数据来训练提升模型在这些方面的能力。
- 知识混淆度高:在问答场景中,召回精度有限,模型需要先从大量相关知识片段中找到有效答案,这个过程在政务等领域难度很大,需要通过增加噪声数据来强化模型的知识搜索能力。
- 答案专业度高:在公共服务的客服场景,答案往往没有绝对准确性,资深的客服人员总能给出更有帮助性的答案。用户问题通常含糊,更加考验专业人员的回答能力。因此我们需要通过 DPO 方式训练模型,使模型能够在众多答案中找到最好最优的答案。为此,我们需要分别构造数据,并针对模型做 SFT 和 DPO。
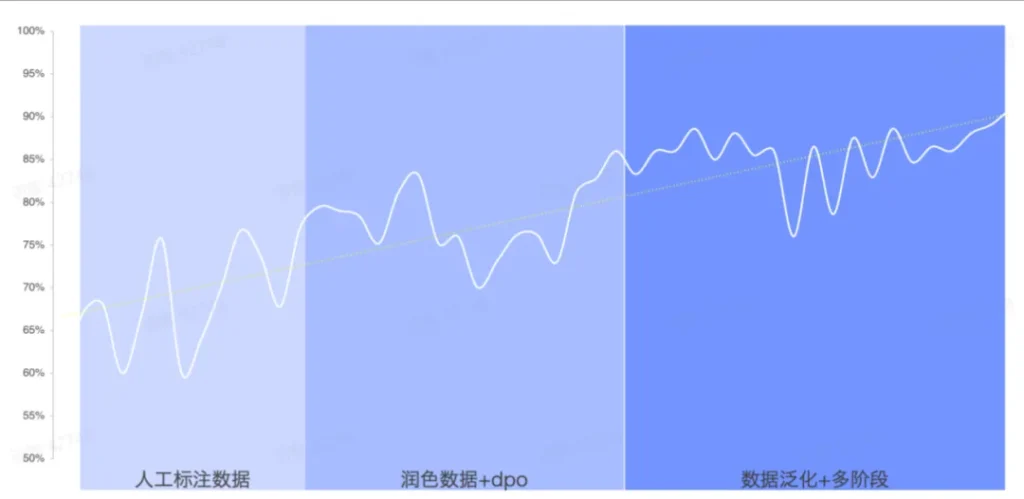
微调后的效果,正确率从 60% 提升到 90% 以上
Leave a Reply