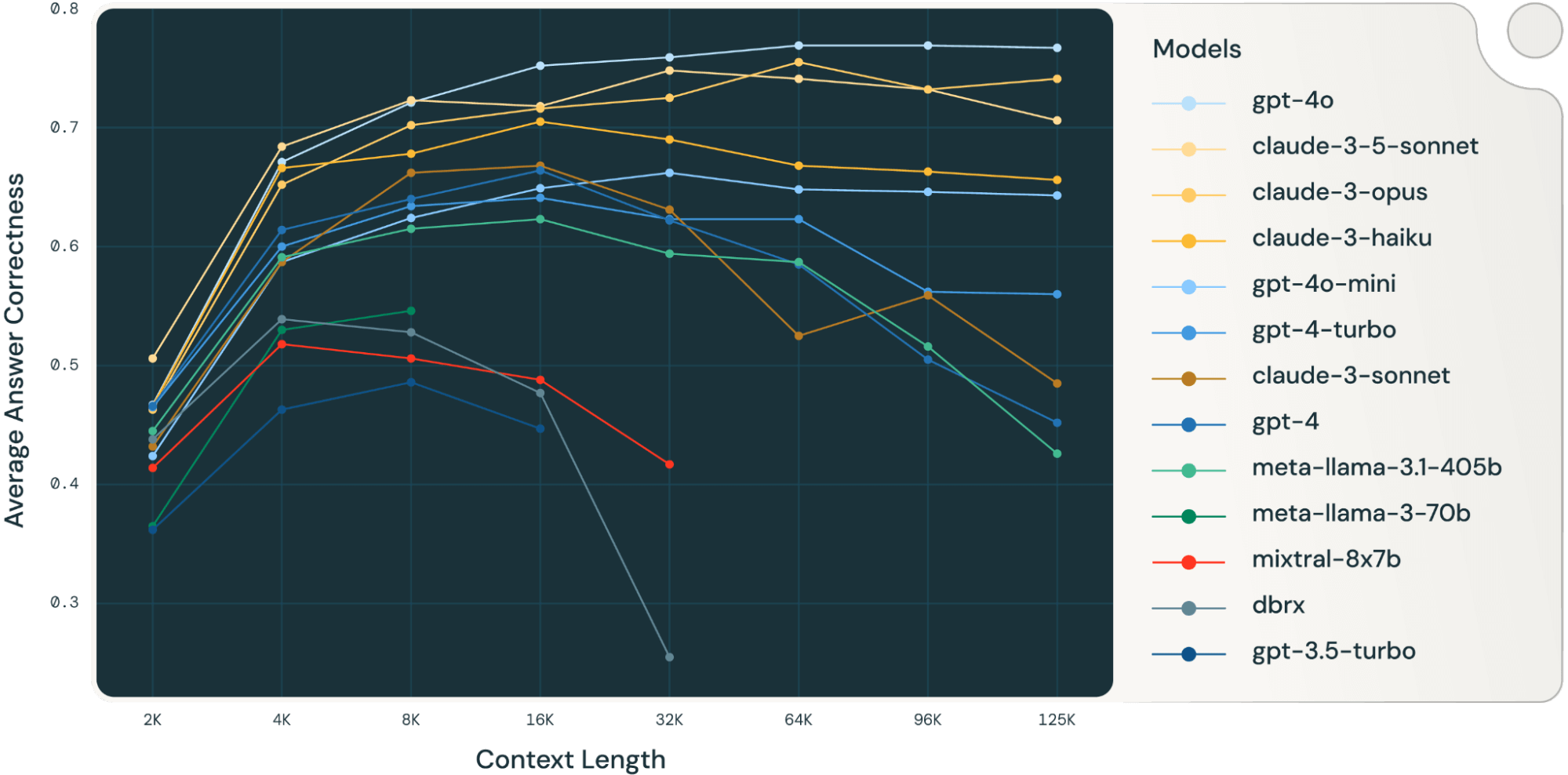
我的评价
- 每个业务都应该基于自己的评测集来测试不同 Context Length 下(或者 TopK Chunk 下)流程的正确率率,包含 Retrieval 和 End-to-End 正确率
- 即使用了 gpt-4o / claude-3.5-sonnet 这种顶级模型,基于 RAG 技术的文档问答端到端正确率天花板也在 70% 左右
整体结果
四项评测集的平均正确率
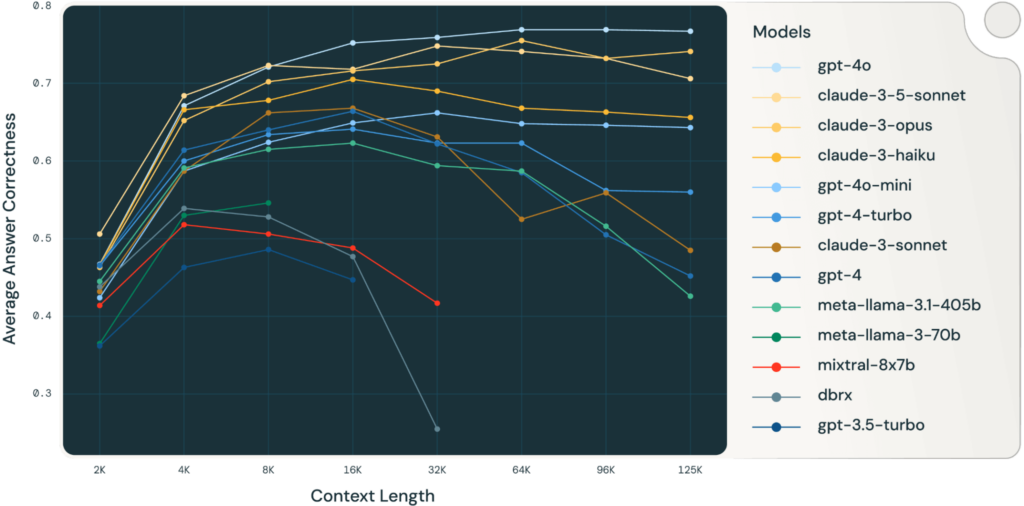
DocQA 的正确率
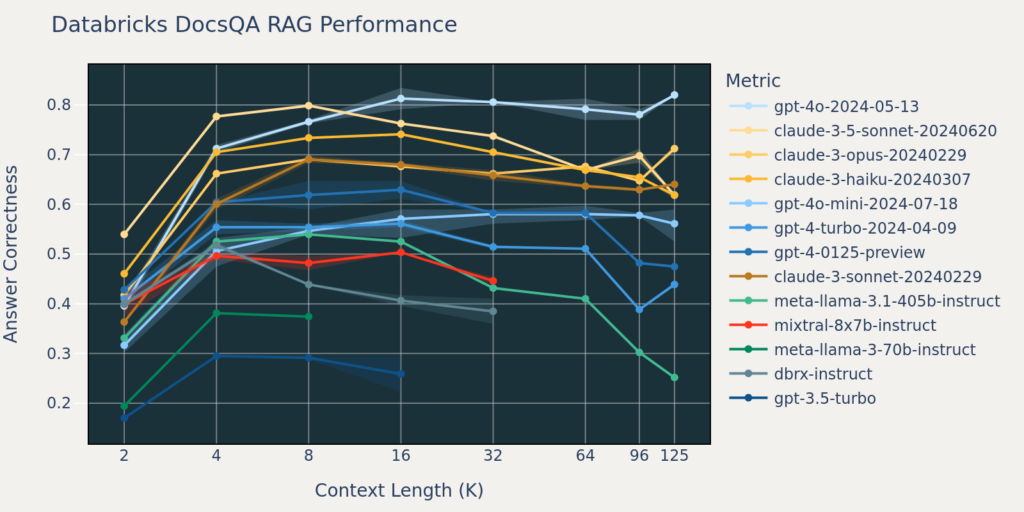
HotpotQA 的正确率
评测方案
评测方案中的主要设置
retrieval 阶段
- Embedding:text-embedding-3-large
- Chunk Size:512 tokens
- Chunk Overlap:256 tokens
- Vector Store:FAISS
generation 阶段
- 模型:gpt-4o, claude-3-5-sonnet, claude-3-opus, etc.
- temperature: 0
- max_output_tokens: 1024
召回率 Recall@k
| # Retrieved chunks | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 |
| Recall@k \ Context Length | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 |
原文
https://www.databricks.com/blog/long-context-rag-performance-llms
Leave a Reply