ServiceNow 使用 RAG 技术解决什么问题
曾经简单的研究过 ServiceNow 这家公司的产品,了解到它主要是围绕 ITSM / 低代码领域做企业流程。
The context is an enterprise company that deploys several GenAI applications that currently rely or will rely on RAG: Flow Generation, Playbook Generation, and Code Generation. Workflows are step-by-step processes that automate one or more goals while playbooks contain workflows and other UI components such as forms. The objective of these applications is to generate domain-specific workflows, playbooks, and code from textual input.
这里的背景是一家企业部署了众多 Gen-AI 应用,它们当前依赖或者未来会依赖 RAG,包括:Flow 生成,Playbook 生成,Code 生成。Workflow 是一步步的自动化一个或多个目标的流程,playbook 包含 workflow 和别的组件如表单。这些 Gen-AI 应用的目的是从文本输入,生成领域内的 workflow,playbook 和 code
The problem we are trying to solve is then: how to adapt the retrieval step to a specific domain and to a variety of retrieval tasks?
ServiceNow 要解决的问题是:怎样把 RAG 流程中的 Retrieval 步骤适配到特定领域知识内、以及适配到多种检索任务中
For our solution, we fine-tune mGTE because of its large context length (8,192 tokens), allowing it to receive long instructions, and because of its multilingual capabilities. We compare it with BM25, a simple yet powerful term-frequency method, and with recent open source multilingual embedding models: mE5 and mGTE.
ServiceNow 的办法是:Fine-tuning mGTE 模型,因为这个模型 Context Length 有 8k 所以支持接受长指令,并且它也是多语言的。他们用精调模型来对比了 BM25、mE5 和 mGTE 模型

精调效果评测
多任务检索
Table 3 shows that downsampling the data causes an improvement of 8% in step retrieval with a small loss in field retrieval, on a fine-tuned mGTE-base model.
These findings suggest that when fine-tuning a retriever for RAG, one needs to be careful on the dataset make-up.
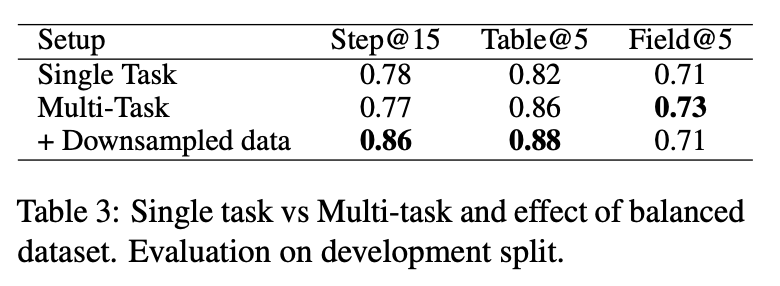
下采样给 step 场景的检索提升了 8% 同时造成 field 场景的检索有少量下降。说明在处理特定领域的数据时,需要关注数据分布的不平衡问题。
与对照模型对比
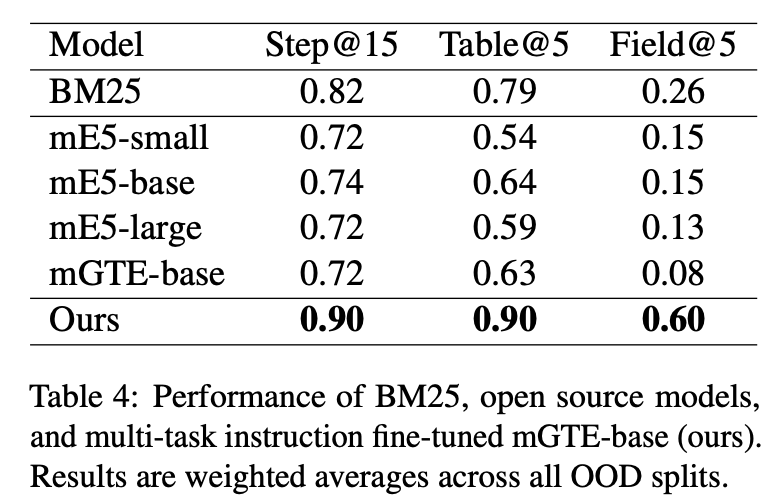
在 OOD(训练数据域外)下精调模型与对照模型对比,在不同场景下的召回准确性比 BM25 模型、mE5 的 small/base/large、mGTE base 模型效果都好,有 16% ~ 26% 的提升
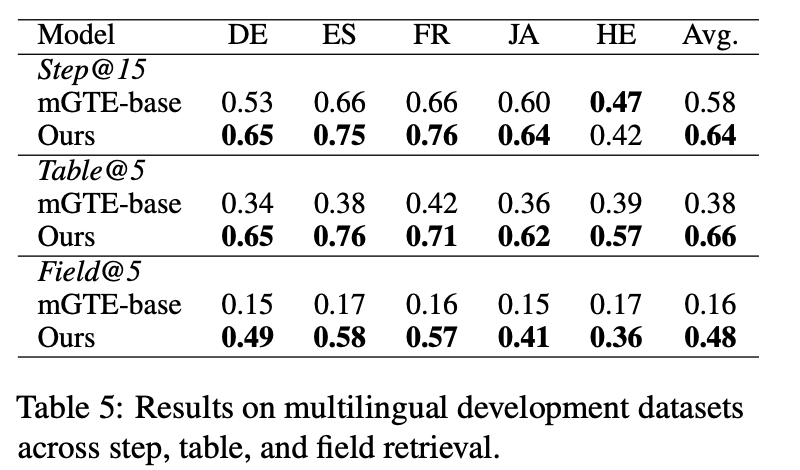
在多语言方面,由于基座模型 mGTE-base 支持多语言,训练数据也通过翻译构造了多语言。在多语言的召回正确性上都有提升
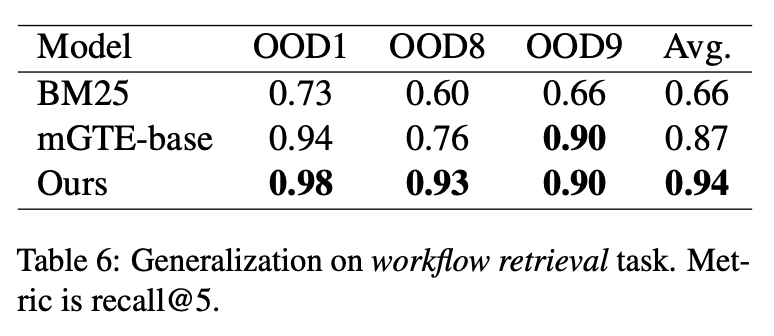
在泛化能力方面,模型在 workflow 场景的召回准确性也有提升,显示出了泛化能力
Leave a Reply