Deep Research 是什么,为什么值得研究
当我们要在不熟悉的领域研究一个话题时,离不开搜索引擎。传统搜索费时费力,即便是新兴AI搜索(如Perplexity),也多止于浅层问答,难以进行扩展性搜索和深度调研。为此,Deep Research 应运而生:它能将模糊的研究任务拆解细化,在海量网络信息中主动搜索、筛选、乃至反思迭代,最终呈现一份条理清晰、内容详实的研究报告,而非零散观点。
Deep Research 的核心在于其自主思考的智能体(Agent)形态。它能主动规划路径,执行多步探索,并在过程中回顾调整。更关键的是,其背后的模型(如 Gemini)支持高达上百万 Token 的上下文,使其能 “记住” 并消化海量信息,将散落的线索编织成富有洞察的分析,生成真正具备深度和连贯性的研究成果。这种化繁为简、提炼真知的能力,正预示着研究方式的深刻变革,极具探索价值。
目前,OpenAI 与 Google Gemini 在都提供了 Deep Research 产品。与 OpenAI Deep Research 仅限付费用户使用不同,Gemini Deep Research 提供了免费体验,还使用了最强大的 Gemini 2.5 Pro 模型,也对用户开放了模型内部的思考 (Think) 过程。因此 Gemini Deep Research 非常值得学习研究。
由于我的工作就包括基于 RAG 技术的 AI 产品,持续了 2 年时间,见证着 RAG 相关技术的发展演进。但也深刻感受到基础 RAG 技术存在很多难题,很难达到端到端高成功率的产品要求。 RAG 中一个重要的环节就是对用户 query 的理解,还没有很好的办法来提升对 query 的理解和改写的水平。于是决定使用 Gemini Deep Research 来研究这个话题。
这一次 Gemini Deep Research 用了几分钟时间,研究了 100 多篇技术文章和论文,最终生成了一篇不错的研究报告。而更吸引我的是 Gemini Deep Research 的思考 (Think) 过程。分析完思考过程,我发现了 Deep Research 这个产品的实现路径,这个收获比 Deep Research 生成的研究报告本身更有价值。
向 Deep Research 提出研究话题
我在 Gemini Deep Research 提出的需求是:
在构建基于 RAG 技术 的产品时,对用户真实 query 的解析、转换非常重要,因为不管是基于 keyword 关键字搜索,或者基于 semantic similarity 的搜索,都要求 query 要与知识库空间接近。而用户 query 通常是个性化、语义不全、包含复杂限定条件或复合型问题
现在研究一下这个技术有哪些主流的方案,要求资料来源应该是大型科技公司、成熟的论文等值得信赖的源头。要以英文材料为主
首先,我给出了研究话题的背景:对用户 query 的理解很难也很重要。然后,提出了用户 query 几个特点:个性化、语义不全、复杂限定条件、复合型问题。
可以看到,这是从没有太多相关知识背景的人的角度提出的问题,所以只能初步的描述问题,无法给出研究思路、或者搜索关键字。
Gemini Deep Research 给出了一份研究方案,如下所示:
Gemini Deep Research 的研究方案
Deep Research 生成的这份研究方案非常重要,我来详细的解读一下

- 第(1)条是细化了研究话题的基础概念、材料来源限制,属于预期之内。
- 第(2)条是细化了针对 ”查询个性化“ 和 ”语义不全” 问题的研究方向(或者说搜索关键词),这里列出了 “查询重写”、“查询扩展”、“上下文注入” 的术语。
- 第(3)条是细化了针对 “复杂限定条件“ 和 ”复合型查询“ 的研究方向(或者说搜索关键词),列出了 “查询分解”、“结构化查询生成”、“多轮查询交互”。
- 第(4)条是额外提及使用 LLM 来解决 query 转换的方向。然而我的 query 中并没有提及 LLM 以及 few-shot、zero-shot、fine-tuning 等技术。
- 第(5)条是提到了 “假设性稳定嵌入(HyDE)“ 技术,这也是最近 2 年讨论比较多的技术。
- 第(6)、(7)是提到 query 转换的性能评估方案,然后是如何总结生成报告。
以上(2)、(3)、(4)条在我的预料之外。因为 Deep Research 本来就要解决 “query 要如何拆解、生成搜索关键词”,结果 Deep Research 直接在研究方案里给出了关键词。并且可以从后续的几轮迭代过程看到,这里研究方向(关键词)非常重要,直接决定了 Deep Research 要怎么执行。
那么这是 Deep Research 内部先通过一次 RAG 来找到关键词的吗?这就变成一个鸡生蛋蛋孵鸡的难题。合理推测是:Deep Research 模型经过训练,已经获得了这些知识,直接生成了研究方向(关键词)。
Gemini Deep Research 的 8 轮迭代
Deep Research 总共进行了 8 次迭代,每一轮聚焦部分关键词、初步分析搜索的结果和出现的新方向(关键词),然后规划下一轮迭代目标。
第 1 轮:搜索覆盖了在上一步规划生成的方向(关键词),包括:查询重写、查询扩展、上下文注入、 查询分解、结构化查询生成、多轮交互、HyDE、生成式查询转换。规划下一轮迭代的目标是深入技术细节

第 2 轮:搜索到了查询重写框架技术 DMQR-RAG,查询扩展方法 Flan-T5。规划下一轮迭代的目标是上下文注入、结构化查询生成、多轮交互

第 3 轮:搜索到了分块技术包括语义分块、Agentic分块、分层分块,搜索到用 Agentic RAG 自主管理检索策略,用 Parent Document Retrieval 和 Self-Query Retrieval 处理复杂查询。规划下一轮的目标是上下文注入、结构化查询生成、多轮交互、查询重写、扩展和性能评估

第 4 轮:搜索到了 Agentic 分块、Parent Document Retrieval 和 Self-Query Retrieval,规划下一轮的目标是 DyPRAG、CAR 框架、Text to SQL、Self-Query Retrieval、Rewrite-Retrieve-Read

第 5 轮:搜索了 Self-Query Retrieval、Rewrite-Retrieve-Read 框架,规划下一轮的目标是 DyPRAG、CAR、Text to SQL、mtRAG 基准测试、PR3 框架

第 6 轮:搜索了 Self-Query Retrieval、Rewrite-Retrieve-Read 框架,规划下一轮的目标是 DyPRAG、个性化查询转换

第 7 轮:搜索了 Parametric RAG、Text to SQL,规划下一轮的目标是 Text to SQL、SCQU 策略、个性化、DyPRAG、CAR、mtRAG

第 8 轮:搜索了 Text to SQL、SCQU 策略、Parametric RAG。最终没有找到 DyPRAG、CAR 框架、mtRAG 基准测试的细节。决定结束迭代

这 8 轮迭代中,第 1 轮涉及到的搜索方向(关键词)最完整,在后续轮中不断完善具体的技术细节。但是在后续轮未必能够发现新的搜索方向,同样也要避免模型无限制的发散方向导致无法聚焦在研究任务上。Gemini Deep Research 的 8 轮迭代搜索示意图如下:

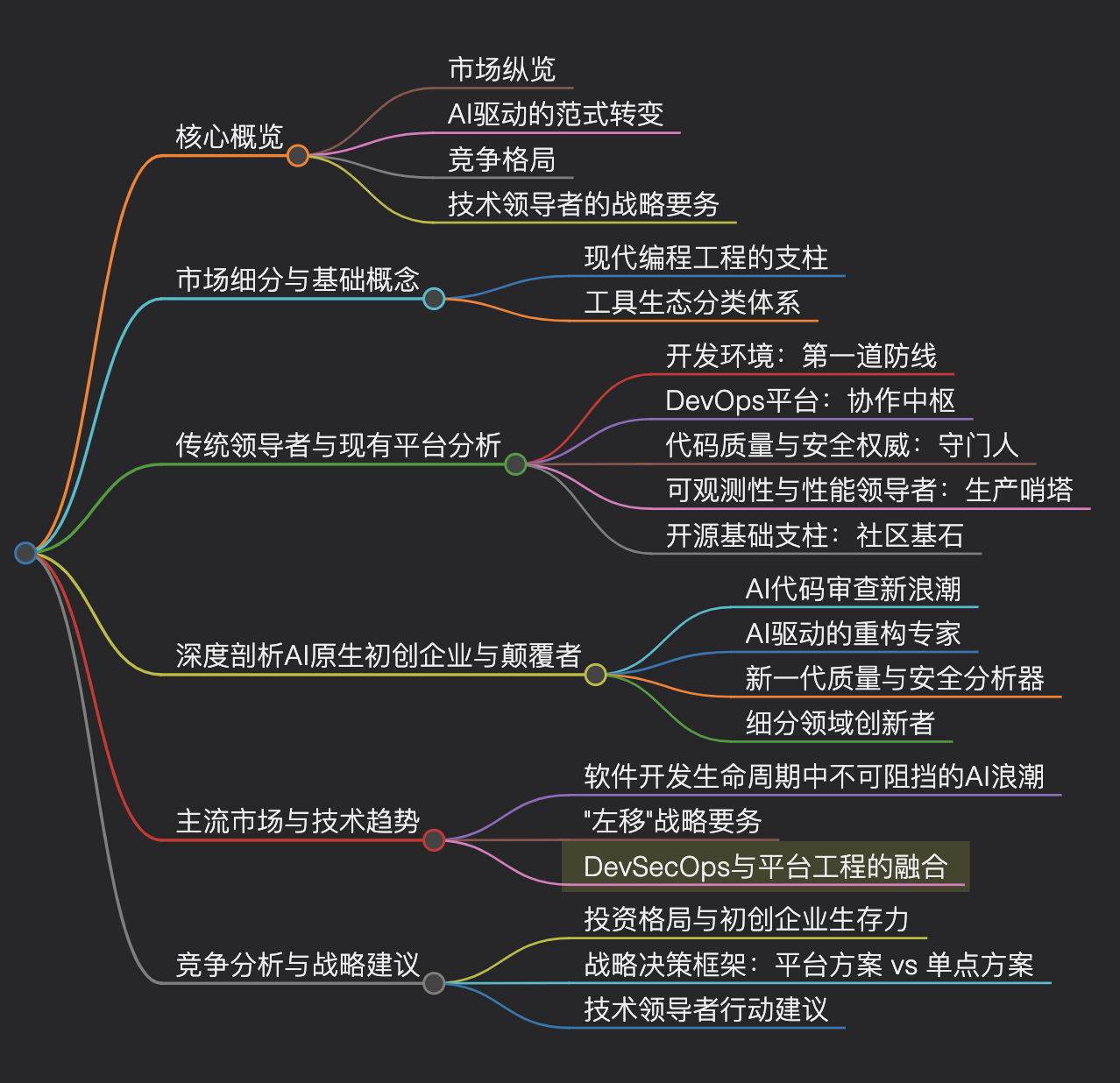
Deep Research生成的研究报告
生成的研究报告的思维导图如下,是一份结构非常工整的报告了,里面提到了技术方法值得仔细研究

对 Gemini Deep Research 的思考
从上述 think 过程的分析可见,Deep Research 采用了包含搜索、思考、规划在内的多轮迭代机制,不断的扩充搜索方向(关键词),直到找不到更多与研究话题相关的关键词后,结束迭代搜索,开始总结生成研究报告。
Deep Research 生成的最初的研究方案非常重要,它决定了整个研究迭代的方向,虽然可以在后续轮次中扩充新关键词,但整体上不会偏离最初的研究方案。
然而 Deep Research 也可能产生幻觉。Deep Research 依赖搜索引擎查找 web 资料,web 资料的准确性、优质程度也会影响 Deep Research 生成的报告质量。Deep Research 自身很难判断一份资料的权威性和准确性。所以 Deep Research 最大的价值是代替人工做了大量的资料搜索、阅读分析,节省了大量人工时间。
Leave a Reply