
标题
HippoRAG: Neurobiologically InspiredLong-Term Memory for Large Language Models
总结
本研究论文提出了一种基于神经生理理论的长期记忆框架 HippoRAG,旨在帮助大型语言模型(LLMs)更有效地整合和检索新知识。
摘要
HippoRAG 是一个受哺乳动物海马索引理论启发的检索框架,用于增强大型语言模型(LLMs)的长期记忆能力。该框架模仿人脑中大脑皮层和海马的不同角色,通过结合 LLMs、知识图谱(KG)和个性化页面排名(Personalized PageRank)算法,实现了对新经验的更深入和高效的知识整合。研究者们将 HippoRAG 与现有的检索增强生成(RAG)方法进行了比较,在多跳问答(QA)任务上展示了显著的性能提升,单步检索的 HippoRAG 在速度和成本上都优于迭代检索方法,如 IRCoT。此外,HippoRAG 能够处理传统 RAG 系统无法解决的新型多跳 QA 场景。
观点
- 大脑的记忆机制: 研究强调了大脑在记忆存储和整合方面的独特机制,即大脑皮层处理感知输入,海马负责索引和检索记忆。
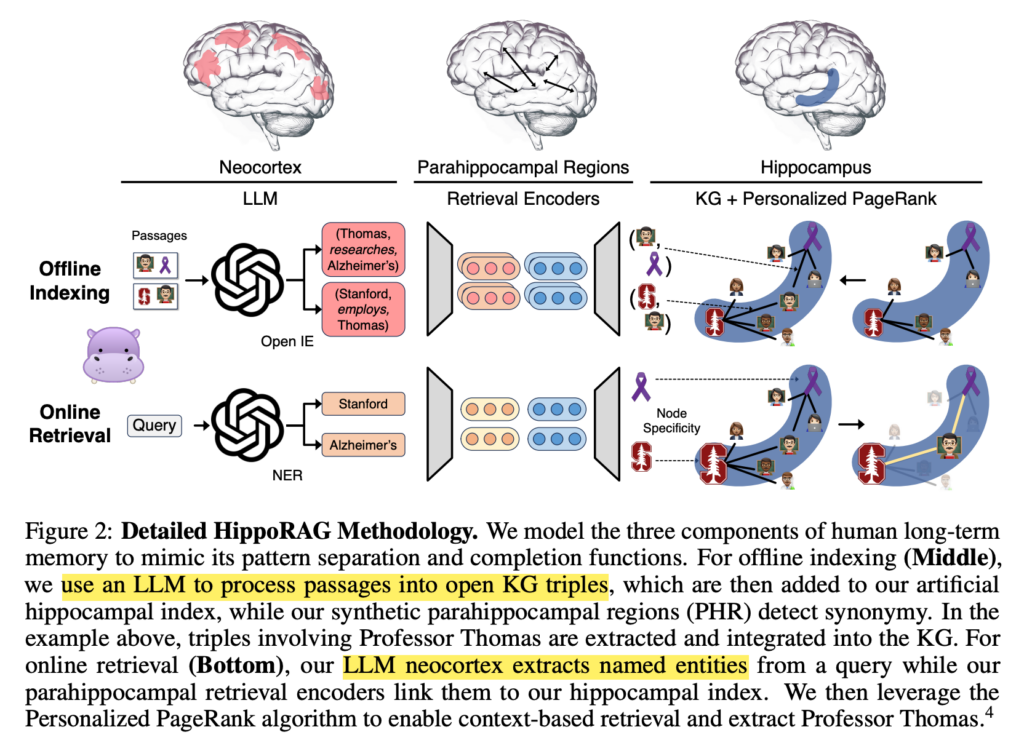
- HippoRAG 的灵感来源: HippoRAG 的设计灵感来源于人类记忆系统的三个组成部分:大脑皮层、海马和颞叶区域,这些部分共同工作以实现模式分离和完成功能。
- 知识图谱的重要性: 通过使用 LLMs 进行开放信息提取(OpenIE),构建了一个无模式的知识图谱,用于模拟人脑的海马索引。
- 个性化页面排名算法的应用: HippoRAG 利用个性化页面排名算法在知识图谱中进行信息搜索,实现跨通过的多跳推理。
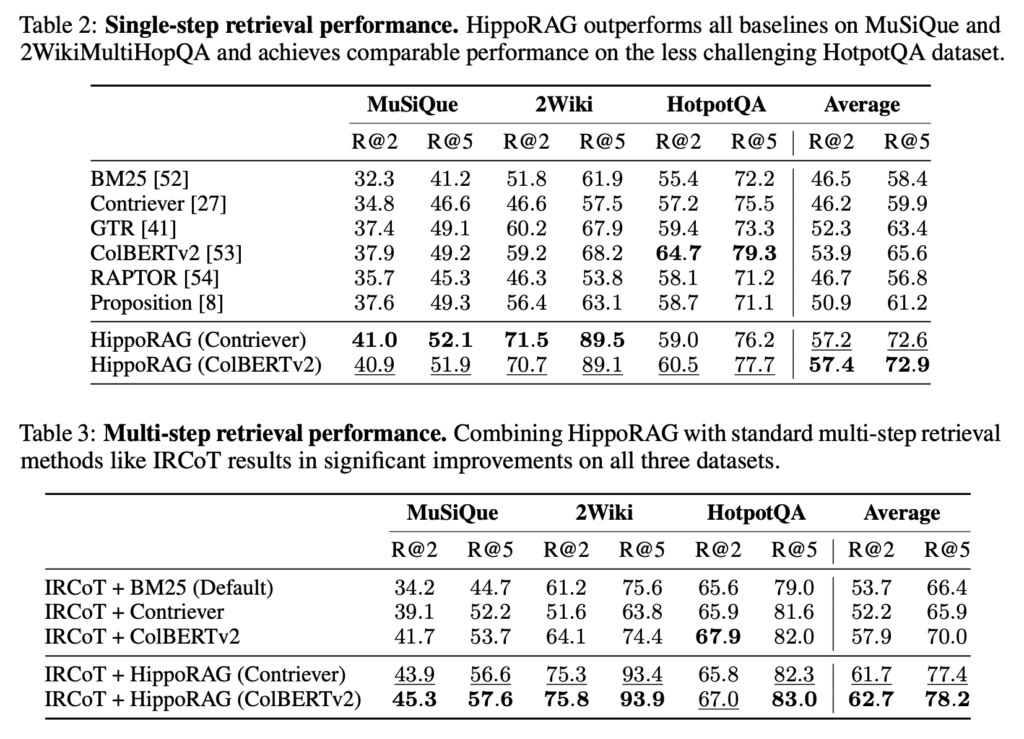
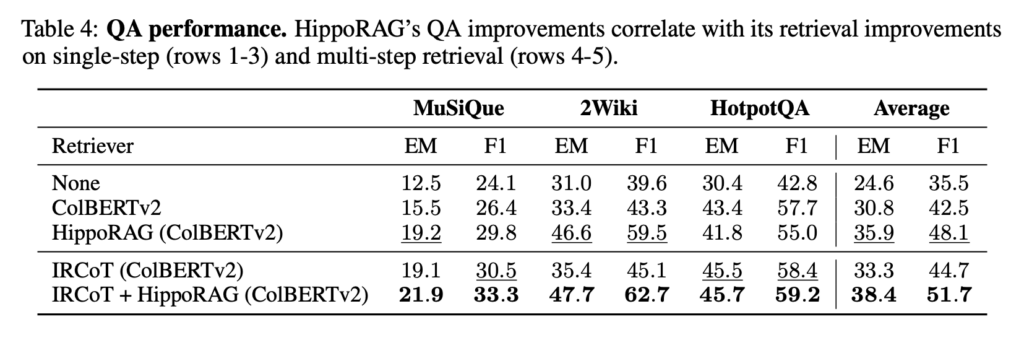
- HippoRAG 与现有方法的比较: 实验结果表明,HippoRAG 在多跳 QA 任务上优于现有的 RAG 方法,包括 BM25、Contriever、GTR 和 ColBERTv2 等。
- HippoRAG 的效率与成本: HippoRAG 的单步检索比迭代检索方法更快速、成本更低,同时在检索性能上具有优势。
- 新型多跳 QA 场景的挑战: 传统的 RAG 方法在处理需要跨多个文档整合信息的问题时存在局限性,而 HippoRAG 能够解决这类问题。
- 未来工作的方向: 研究提出了未来工作的可能方向,包括对 HippoRAG 组件的进一步优化和对大规模知识图谱的可扩展性的验证。
评测结果
HippoRAG的优势
单步多跳检索 在多跳QA中,与传统的RAG方法相比,HippoRAG的一个主要优势是它能够在一个步骤中执行多跳检索。尽管 IRCoT 也可以解决这个多跳检索问题,如附录 G 所示,但在在线检索方面,它的成本比我们的高 10-30 倍,慢 6-13 倍,可以说是服务最终用户时最重要的因素
Leave a Reply