
总结
这篇来自 Google DeepMind 的论文 “Inference Scaling for Long-Context Retrieval Augmented Generation” ,研究了基于 Long-Context LLM 的 RAG 技术,如何随着 Long-Context 长度的 scale 而 scale RAG 的效果,以实现充分利用 Long-Context 能力的目的。
实验结果显示,IterDRAG 方案与标准 RAG 相比,在基准数据集上实现了高达58.9%的提升。
scale Contex-Length
Long-Context 的 LLM(例如 Gemini-1.5-flash 支持 2M token),并非总能有效利用 Long Context 中的上下文知识。在 RAG 方案里,单纯的给 LLM 增加文档数量、无限逼近 LLM 长度极限,会给 LLM 带来困惑,导致最终正确率下降。这个结论在很多的研究论文里得到支持。
DRAG(Demonstration-Based RAG)扩展了标准 RAG 方案,在输入的 prompt(context)中增加了 question-answer 的例子,让 LLM 学会如何从 long context 里提取正确信息、回答问题。在面对复杂的多跳问题(multi-hop)时,DRAG 依然面临挑战。
本文提出了 IterDRAG(Iterative Demonstration-Based RAG)方案,扩展了 DRAG,并探索进一步线性提升 context 长度来提升 RAG 的效果。
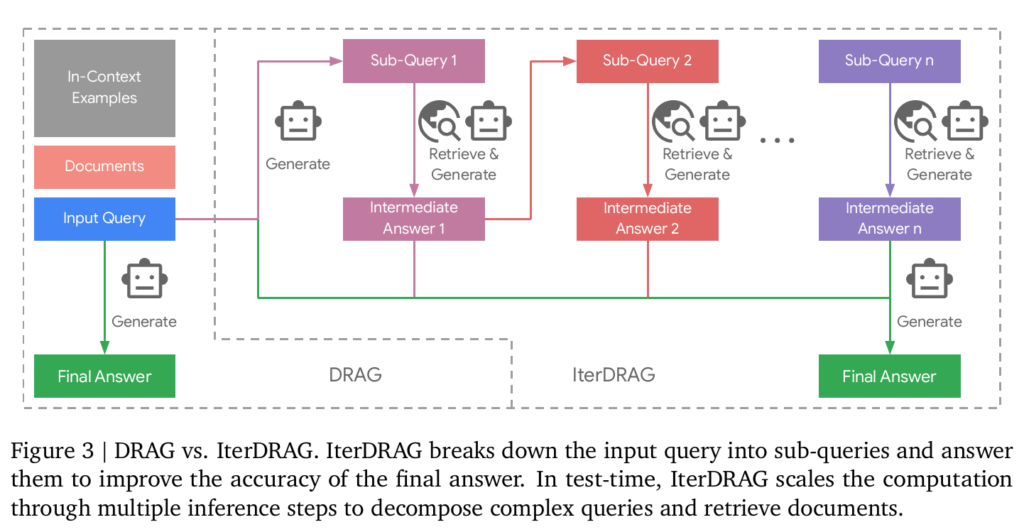
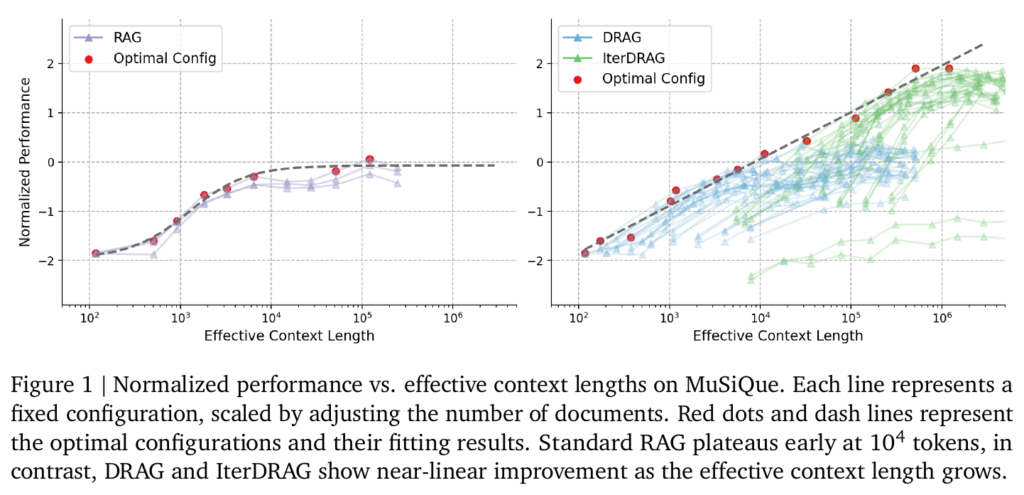
论文的实验结果表明,RAG 在 1k~100k token长度下的性能变化并不大,表明 RAG 无法充分利用 Long-Context LLM 的长上下文的优势。DRAG 可以扩展到 几十k ~ 几百 k 的 token长度并提升性能。而 IterDRAG 可以进一步扩展到 1M 的 token 长度提升性能。
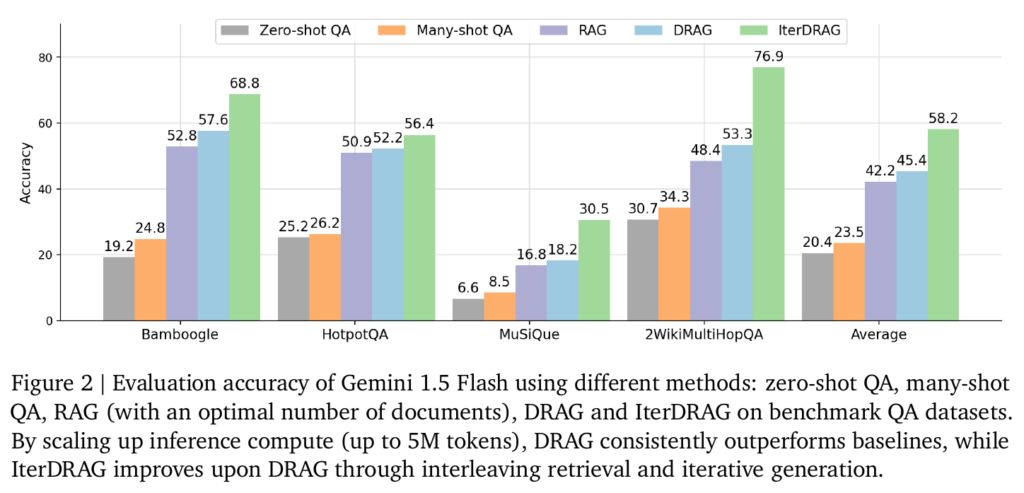
在使用相同模型的条件下,基础 RAG 方案只有 42% 的平均正确率,DRAG 方案有 45% 的平均正确率,IterDRAG 方案做到了 58% 的平均正确率。
可以认为基础 RAG 方案做到 50%左右的正确率已经是不错的效果了,即使提升 5%、10% 都不容易
scale few-shot
DRAG 方案给 context 增加了 few-shot,能提升最终的正确率。论文也评测了随着 few-shot 数增加 DRAG/IterDRAG 正确率的提升趋势。可以看到,增加文档数相比增加 few-shot 数,对提升最终正确率更有效果。
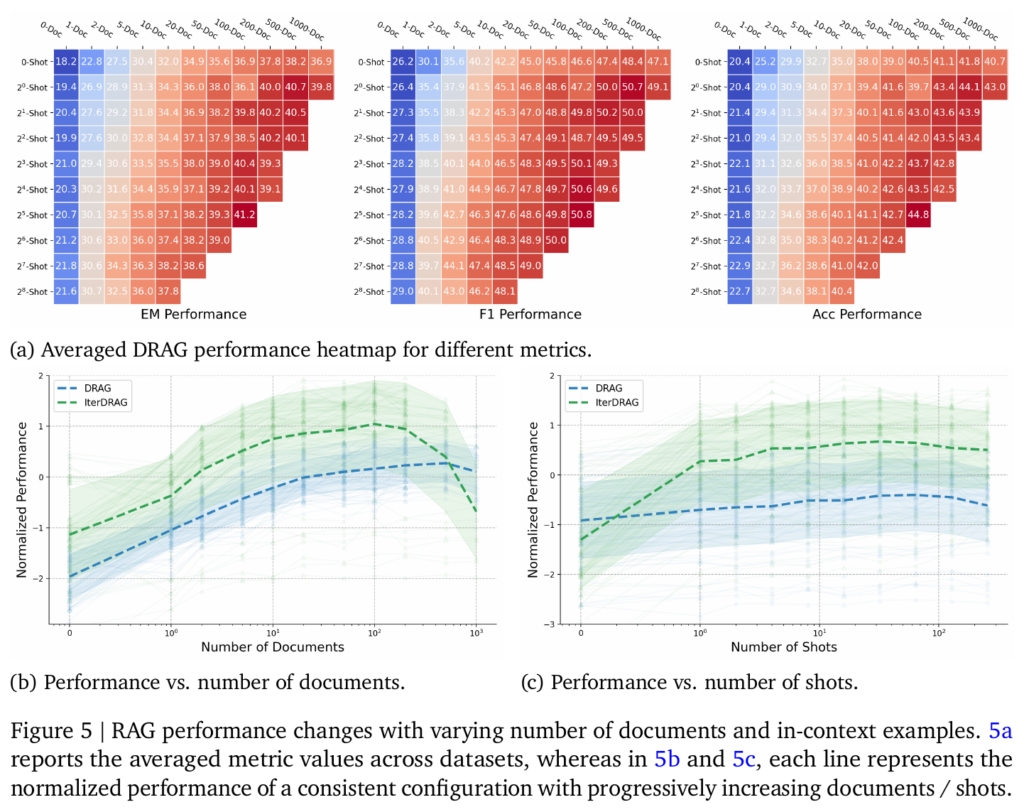
scale retrieval
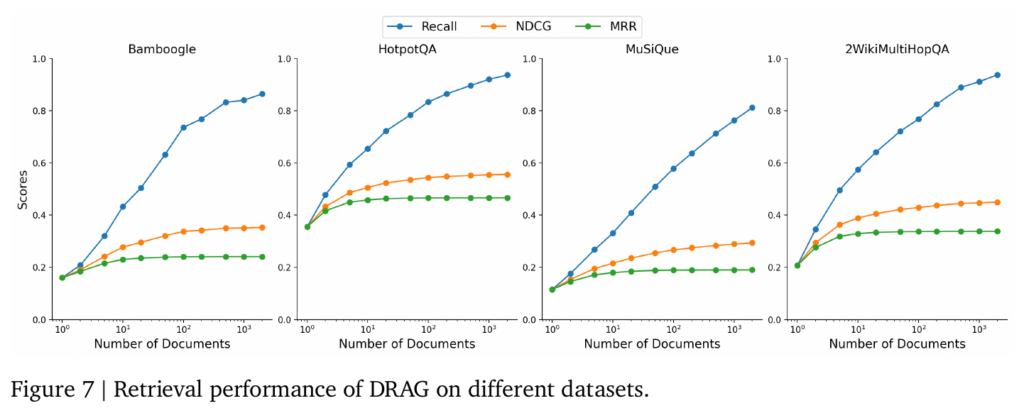
Retrieval 阶段,简单的提升文档数目可以快速的提升 Recall 正确率
arXiv 链接
https://arxiv.org/pdf/2410.04343