导语
Apple 最新版 M4 芯片上市后,大家对在 Mac M4 上本地部署 LLM 热情不减。M 芯片的统一内存架构确实降低了 LLM 本地部署的门槛,只要内存能放得下的 LLM,就能运行起来。不像 Windows 下部署 LLM 是对 GPU VRAM 有要求,但 NVIDIA 的大内存 GPU 又稀有又昂贵。
然后 Mac M4 上部署的 LLM 效果到底怎么样呢?为了体验本地部署 LLM 而购买 Macbook/Macmini 值得吗?本文专门评测了一下
评测1:M2 Pro vs. M4 vs. M4 Pro vs. RTX 2080ti
评测办法
使用 LM Studio 工具在本地加载 LLM,LM Studio 会在对话末尾显示输出的 tok/sec、tokens、first token time。
使用 prompt 是让 DeepSeek 用 javascript 画一个太阳系 write a java script to simulate solar system include sun and planets。
使用的模型是 DeepSeek-R1-Distill-Qwen-14b,统一使用 Q8_0 量化版本。R1 模型的输出包含 Think 部分,时间比较长,统计出的 tok/sec 会更准确。
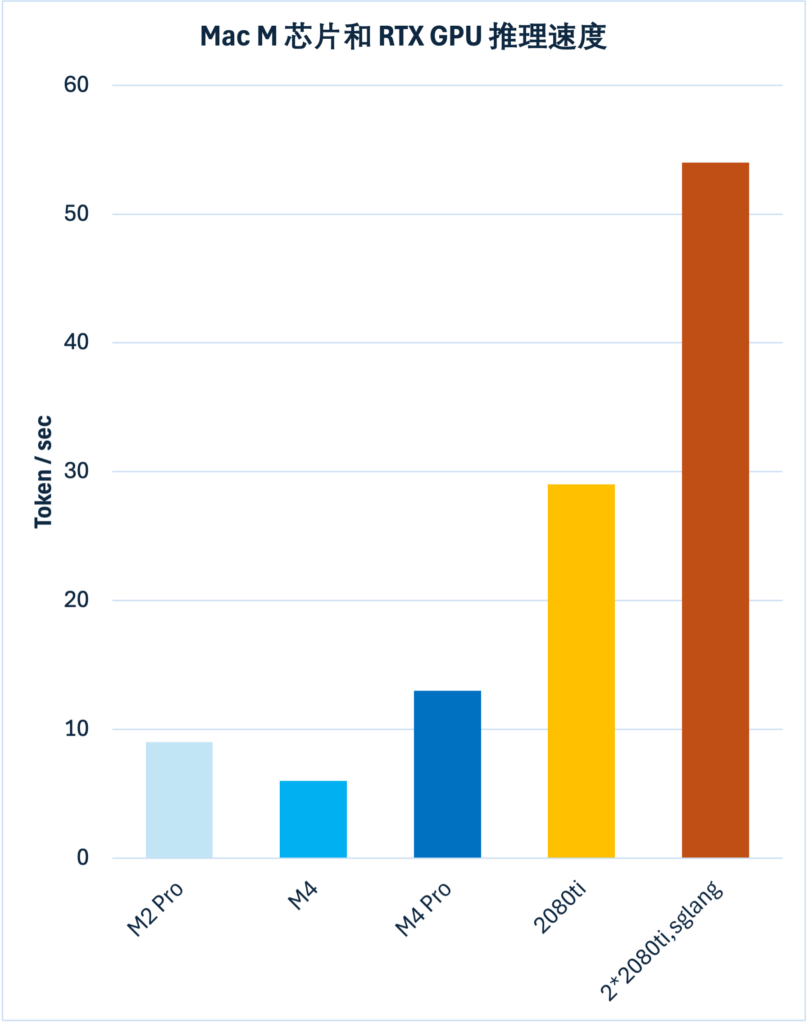
我手头有 Macbook M2 Pro, MacMini M4, RTX 2080ti,加上找朋友借用的 MacMini M4 Pro 顶配,总共 4 款设备。评测结果如下图
结论:
- Mac M4 的速度约等于 RTX 2080ti 的一半
- M4 丐版的速度约等于 M4 Pro 顶配的一半,是 RTX 2080ti 的 1/4
- M4 的速度还不如 M2 Pro,是 M2 Pro 的 2/3
作为参照的是用 SGLang 框架在 2 张 2080ti 上并行推理的速度。
评测2:RTX 2080ti vs. RTX 4090 vs. L20
评测方法
使用 SGLang 推理框架运行大模型,使用 SGLang 官方的 benchmark 命令评测不同并发下的吞吐量 tok/sec。
使用的模型是 DeepSeek-R1-Distill-Qwen-7b,fp16 无量化版。
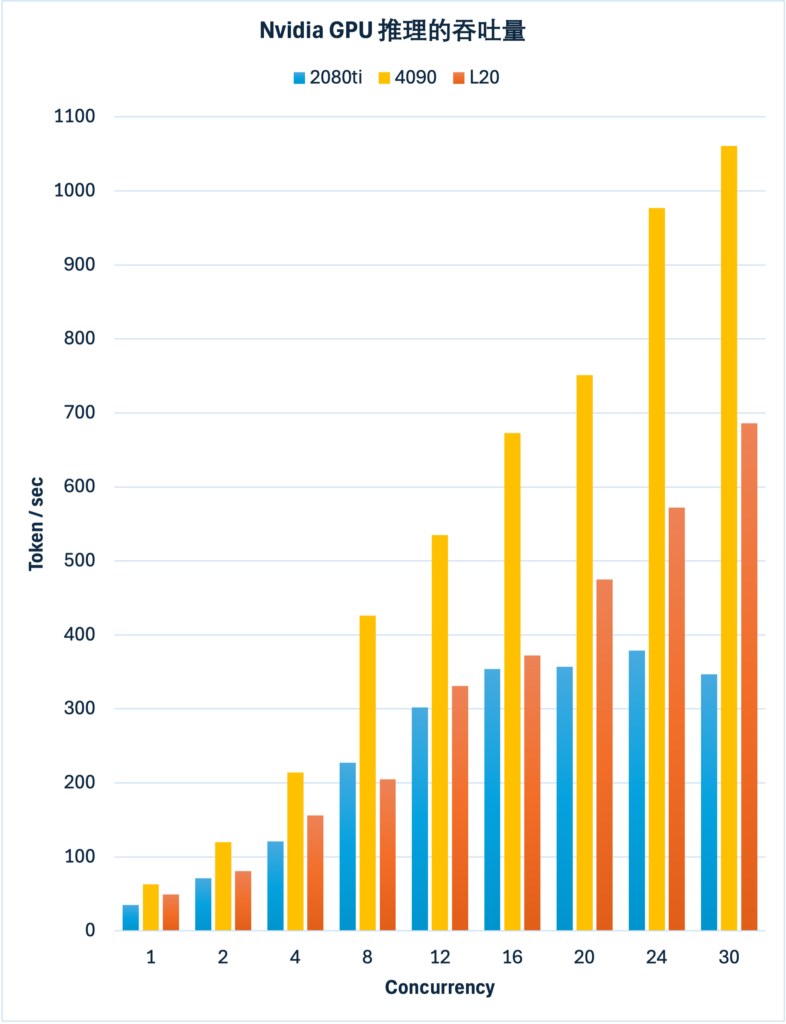
我本地有两张 RTX2080ti,租用云上 GPU 租了 RTX 4090 和 L20。评测结果如图
结论:
- RTX 2080ti在并发 12~16 时总吞吐量达到峰值,压不上去了
- L20 比 2080ti 好一些,小并发时差距不明显,但是能支持更高的并发能力,天花板更高
- RTX 4090 是最强的,总体吞吐量、能支持的并发能力,都显著高于 L20
Leave a Reply