
总结
本研究通过引入控制令牌(Control Token, CT)并结合密集段落检索(Dense Passage Retrieval, DPR)模型,提高了大型语言模型(LLMs)中的信息检索准确性,特别是在特定领域的文档检索方面。
摘要
研究团队采用了基于深度学习的搜索引擎技术,即密集段落检索(DPR)模型,并通过引入控制令牌(CT)来增强其性能。CT 是一种特殊的令牌,用于表示查询的意图类别,它通过与查询和文档文本结合,帮助模型更准确地理解用户的检索意图。研究选择了 AIHUB MRC 数据集,该数据集包含多种类型的复杂文档,并针对 ko 文本进行了优化。通过对 DPR 模型进行微调,使其能够处理包含 CT 的输入数据,研究者们开发了一种名为 cDPR 的模型。实验结果表明,与标准的 DPR 模型相比,cDPR 模型在 Top-1 和 Top-20 的检索准确率上分别提高了 13% 和 4%。此外,研究还探讨了不同的 CT 分类阈值对模型性能的影响,并发现了更高的分类阈值通常能带来更好的检索性能。
方法
聊天机器人搜索引擎的核心是了解用户意图。准确理解用户意图对于缩小搜索范围和提供高度准确的搜索结果至关重要。然而,现有的 DPR 模型的局限性在于它缺乏对用户意图的反思,仅依赖于文本相似性。因此,我们设计了一种将用户意图与 DPR 模型相结合的新方法
我们的研究目标是通过在输入中加入 CT 来微调 DPR 模型以提高搜索准确性。具体来说,CT 表示用户对特定文档的查询意图。例如,当用户查询特定域时,将特定于域的 CT 添加到输入中,使模型能够提供更准确的搜索结果。我们用包含 CT 的输入训练了 DPR 模型,以开发一个能够有效检索与用户意图相关的文档的系统,从而显着提高搜索准确性。图 1 显示了整个工艺流程。我们将这种 CT 和 DPR 的组合模型称为 cDPR。
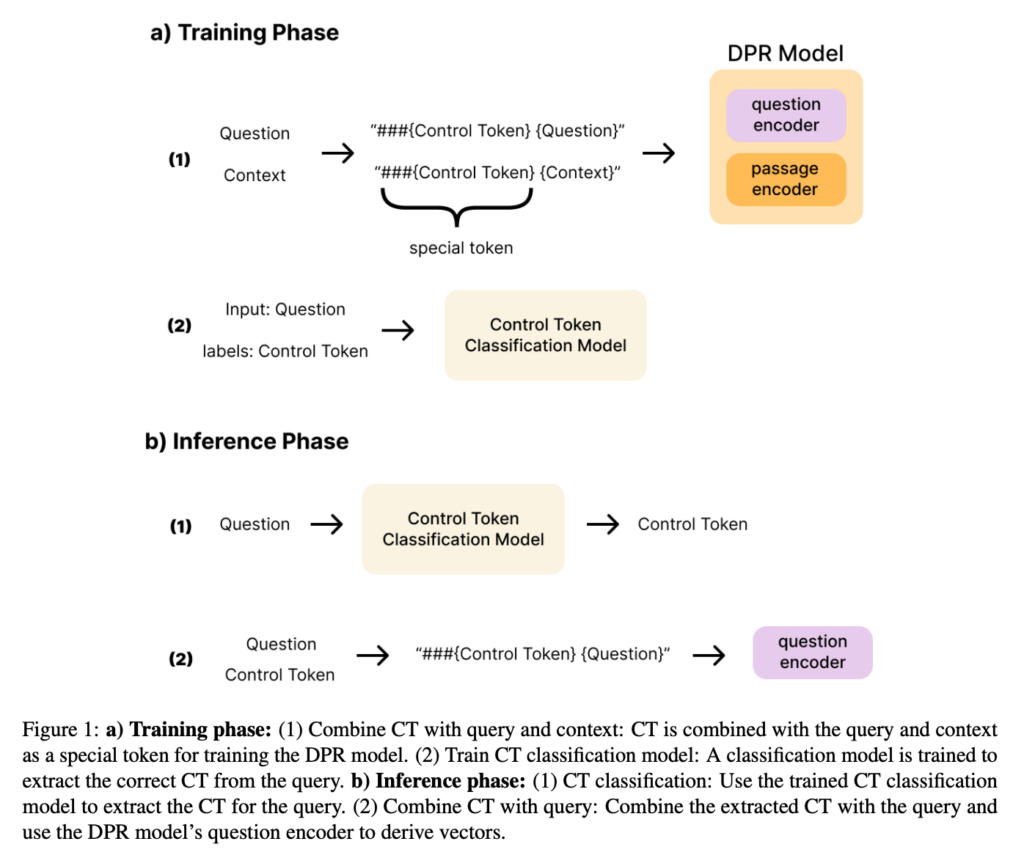
效果
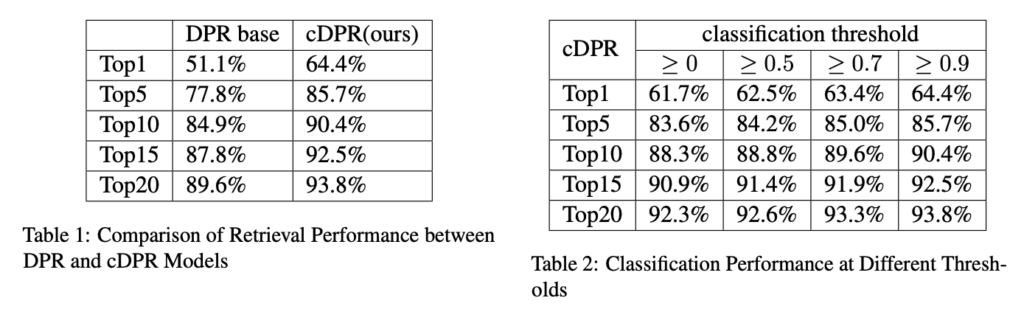
实验结果表明,与标准的 DPR 模型相比,cDPR 模型在 Top-1 和 Top-20 的检索准确率上分别提高了 13% 和 4%。此外,研究还探讨了不同的 CT 分类阈值对模型性能的影响,并发现了更高的分类阈值通常能带来更好的检索性能。
相关资料
DPR 模型
DPR 模型 2004.04906v2 (arxiv.org)
DPR 模型跟 dense text embedding 模型的区别
DPR(Dense Passage Retrieval)模型与密集文本嵌入模型的区别主要在于它们的设计目标和应用场景。
- DPR 模型:
- DPR 是一个专门为开放领域问答任务设计的检索模型。
- 它使用两个独立的 BERT 模型作为编码器,一个用于编码查询(question encoder),另一个用于编码文本段落(passage encoder)。
- DPR 的目标是将查询和文本段落转换为高维向量,并通过向量之间的余弦相似度来评估它们的相关性。
- DPR 模型的训练过程旨在确保相关的查询和段落对在向量空间中的位置更接近,从而在检索时能够高效地找到最相关的文本段落。
- 密集文本嵌入模型(如 SentenceTransformer 等):
- 这类模型的目标是将任意长度的文本转换为固定大小的向量表示,以便在各种自然语言处理任务中使用,如文本相似性计算、聚类、信息检索等。
- 它们通常使用单一的编码器模型,如 BERT 或其他变体,来生成文本的嵌入表示。
- 密集文本嵌入模型的训练可能包括多种任务,如自然语言推断(NLI)、语义相似性判断等,以确保生成的嵌入在语义上是有意义的。
- 这些模型的输出是文本的语义表示,可以用于各种下游任务,而不仅限于检索。
总结来说,DPR 模型专注于检索任务,通过优化查询和文本段落之间的相似度匹配来提高检索的准确性;而密集文本嵌入模型则提供了一种通用的文本表示方法,可以用于多种不同的 NLP 任务,其生成的嵌入旨在捕捉文本的深层语义信息。
DPR 模型与 ColBERT 模型的区别
DPR(Dense Passage Retrieval)模型和ColBERT(Collaborative BERT)模型都是用于信息检索的先进技术,但它们在设计和工作原理上有所不同:
DPR模型:
- DPR是一种基于双塔(dual-encoder)架构的模型,它将查询和文档(或段落)独立编码成向量。
- 查询和文档的向量表示在一个共享的高维空间中,通过向量间的点积相似度来衡量它们之间的匹配程度。
- DPR模型训练的目标是使得相关的查询和文档对之间的向量点积得分高,而不相关的对之间的得分低。
- DPR模型在训练时使用了对比学习(contrastive learning)的方法,通过正样本(正确的查询-文档对)和负样本(错误的查询-文档对)来学习更好的向量表示。
ColBERT模型:
- ColBERT也是基于BERT的模型,但它采用了一个更为复杂的架构,即延迟(late)交互架构。
- 在ColBERT中,查询和文档被编码成多个向量(每个词或词片段一个向量),而不是单个的向量。
- ColBERT在检索时会计算查询向量和文档向量之间的最大化相似度(max-similarity),这允许模型在更细粒度的层面上进行匹配。
- ColBERT的这种设计允许它在不牺牲速度的前提下,达到与复杂的交互式模型相当的精度。
区别总结:
- 向量表示: DPR使用单个向量表示查询和文档,而ColBERT使用多个向量来表示每个词或词片段。
- 匹配方式: DPR通过点积相似度进行匹配,ColBERT则通过最大化相似度进行词级别的匹配。
- 模型架构: DPR采用双塔架构,ColBERT采用延迟交互架构。
- 训练目标: DPR通过对比学习使正样本得分高于负样本,ColBERT则通过最大化相似度来优化。
- 检索效率: DPR可以通过向量索引来加速检索,而ColBERT虽然在精度上有优势,但在检索效率上可能会略逊一筹,因为它需要计算更多的向量之间的相似度。
两种模型都在信息检索领域取得了显著的进步,但它们各自适用于不同的场景和需求。DPR因其简单和高效而受到青睐,而ColBERT则在精度要求更高的场景中表现出色。
Leave a Reply