
poppler 是一个用于 PDF 提取、转换、修改等用途的 lib 库,功能强大,速度飞快。
本文里使用 https://arxiv.org/abs/2411.03628 这篇 PDF 来演示 poppler 的用途。
安装 poppler
在 Ubuntu 下可以安装 poppler-utils 包 apt install poppler-utils。macOS 下 brew install poppler。
它包含 12 个命令行工具。
Poppler is a PDF rendering library based on Xpdf PDF viewer.
.
This package contains command line utilities (based on Poppler) for getting
information of PDF documents, convert them to other formats, or manipulate
them:
* pdfdetach -- lists or extracts embedded files (attachments)
* pdffonts -- font analyzer
* pdfimages -- image extractor
* pdfinfo -- document information
* pdfseparate -- page extraction tool
* pdfsig -- verifies digital signatures
* pdftocairo -- PDF to PNG/JPEG/PDF/PS/EPS/SVG converter using Cairo
* pdftohtml -- PDF to HTML converter
* pdftoppm -- PDF to PPM/PNG/JPEG image converter
* pdftops -- PDF to PostScript (PS) converter
* pdftotext -- text extraction
* pdfunite -- document merging toolpdfimages–提取 PDF 中的图片
使用 pdfimages 命令来提取 PDF 中的图片
pdfimages -all -p 2411.03628.pdf images例如 PDF 原文档 15 页如下

图片提取出来可能包含多个文件(多个alpha通道?不懂)
pdftoppm–把 PDF 页面转成图片
使用 pdftoppm 直接把 PDF 页面转成图片。支持生成 png、jpg、ppm 格式。
这里提取 PDF 的第 15 页,生成 png 图片。默认按照 ppi 为 150 生成 png。
PDF 文件按 A4 纸大小计算,ppi 是 72。所以指定 ppi 为 150 时,实际上图片被放大为 2 倍。
pdftoppm -l 15 -f 15 -png 2411.03628.pdf images
可以用 -r 参数来指定 ppi(放大倍数)
pdftoppm -l 15 -f 15 -png -r 300 2411.03628.pdf ppm_image_r300pdftoppm 还可以截取 PDF 页面的部分内容而不是整页生成图片。使用x、y、W、H 来指定截取范围。x、y是截图区域的左上角(0坐标是页面的左上角),W、H 是截图区域的宽度和高度
pdftoppm -l 15 -f 15 -png -x 200 -y 100 -W 900 -H 720 2411.03628.pdf ppm_image_crop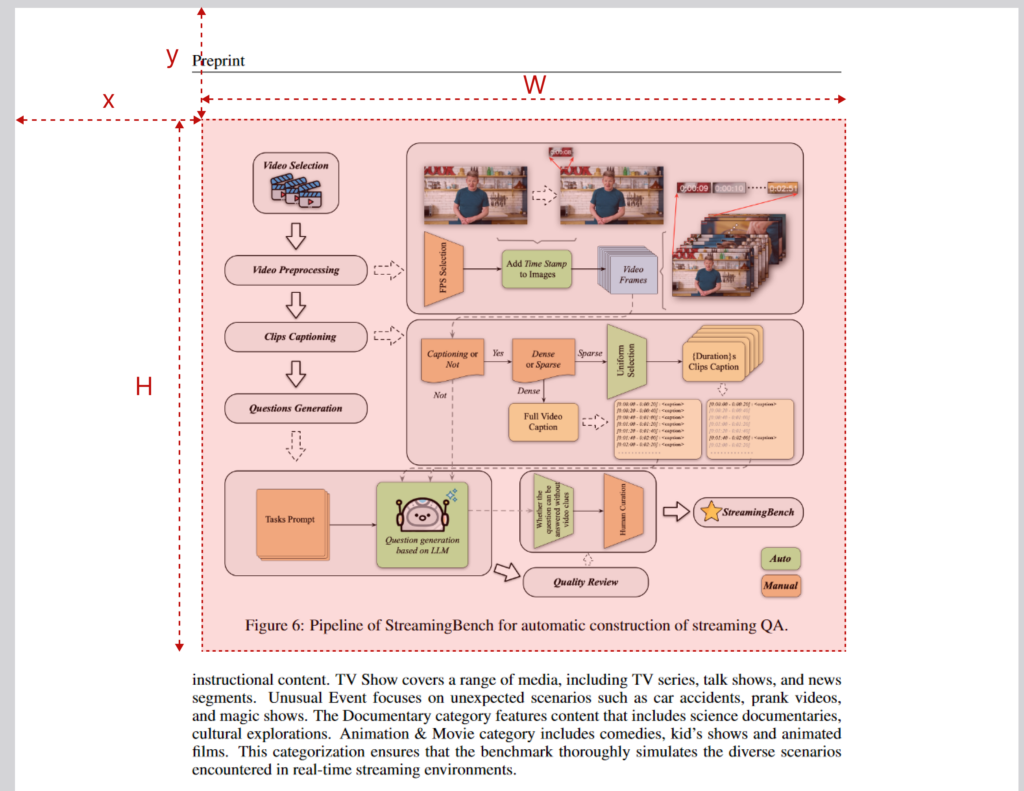
转换并切图的效果
pdftocairo–PDF 页面转成图片 Cairo 版
pdftocairo 支持生成的图片格式更多,支持:png、jpeg、tiff,支持 svg 无损矢量图,支持转成 pdf 文件。同样支持使用x、y、W、H 来指定截取范围,但注意这里的数值是原页面 100% 缩放时的坐标和宽高。
pdftocairo -l 15 -f 15 -svg -x 100 -y 50 -W 450 -H 350 -paperw 450 -paperh 350 2411.03628.pdf image_crop.svg
pdftotext–提取pdf中的文本
pdftotext 直接提取 PDF 中的文本
pdftotext -f 15 -l 15 2411.03628.pdf 03628.txt提取第 15 页的文本如下
Preprint
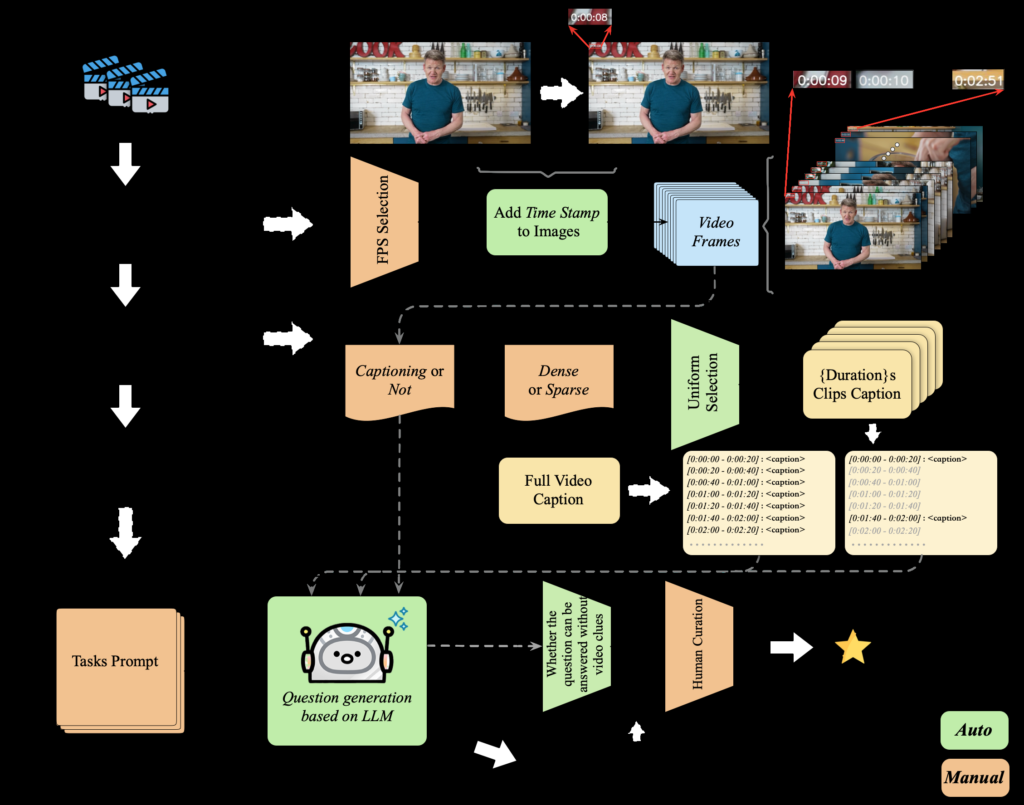
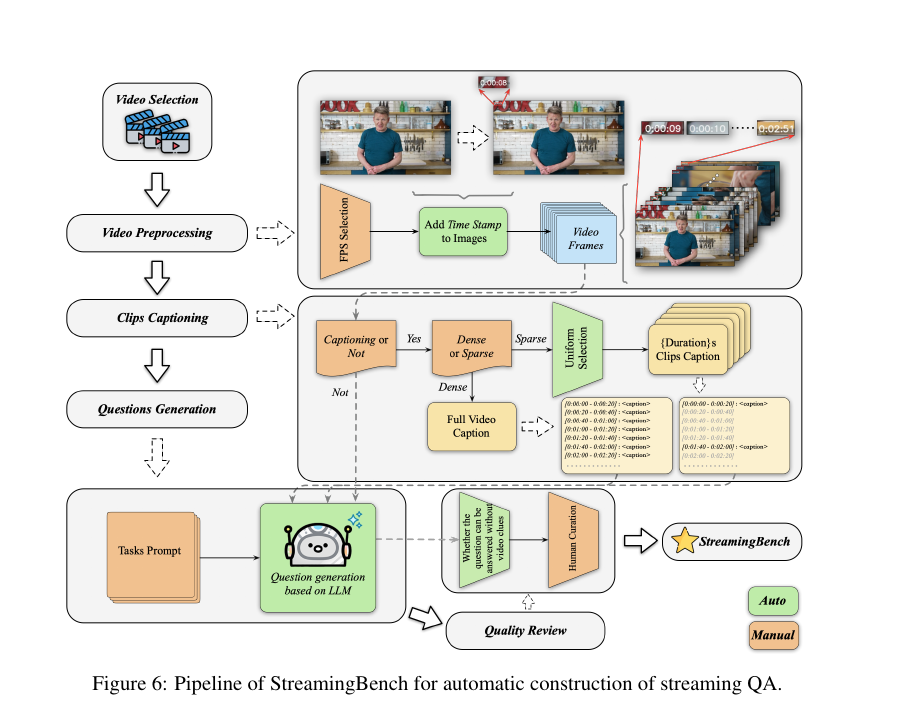
Figure 6: Pipeline of StreamingBench for automatic construction of streaming QA.
instructional content. TV Show covers a range of media, including TV series, talk shows, and news
segments. Unusual Event focuses on unexpected scenarios such as car accidents, prank videos,
and magic shows. The Documentary category features content that includes science documentaries,
cultural explorations. Animation & Movie category includes comedies, kid’s shows and animated
films. This categorization ensures that the benchmark thoroughly simulates the diverse scenarios
encountered in real-time streaming environments.
B.2
QA G ENERATION
To create questions that truly capture the streaming nature of video understandings, we selected
five distinct timestamps for each video to serve as query points. For tasks under the Real-Time
Visual Understanding category and the Proactive Output task, we adapted the traditional two-step
approach of generating questions based on captions. The pipeline for QA Generation is illustrated
in Figure 6. Specifically, we employed GPT-4o to sample frames from the video at a rate of 1 frame
per second (fps). We observed that for Single-Frame tasks, directly generating questions based on
the sampled images, without an intermediate captioning phase, resulted in higher quality questions.
Conversely, for Multi-Frame tasks, generating captions first and then formulating questions from
those captions yielded better results. Unlike other video benchmarks where queries are typically
presented at the end of the video, StreamingBench introduces queries at various points throughout
the video. To automatically generate appropriate query timestamps, we tagged each sampled frame
with its corresponding timestamp in the video. We found that this method helped us produce highquality questions with realistic query timings. Additionally, we tagged each question with the time
range during which the relevant clues appeared in the video, specifying the minimal video segment
necessary to answer the question accurately. This tagging approach also proved effective, ensuring the generation of high-quality, contextually relevant questions. For tasks in the Omni-Source
Understanding category and Contextual Understanding tasks (excluding Proactive Output), where
questions require audio information, we employed meticulous manual annotation. Each video was
carefully annotated to ensure the precision and relevance of the generated questions.
15pdftohtml 把 PDF 转成 html
pdftohtml 可以直接把 PDF 转成 html,内嵌图片、表格、自带链接
pdftohtml -s -f 15 -l 15 2411.03628.pdf 03628.html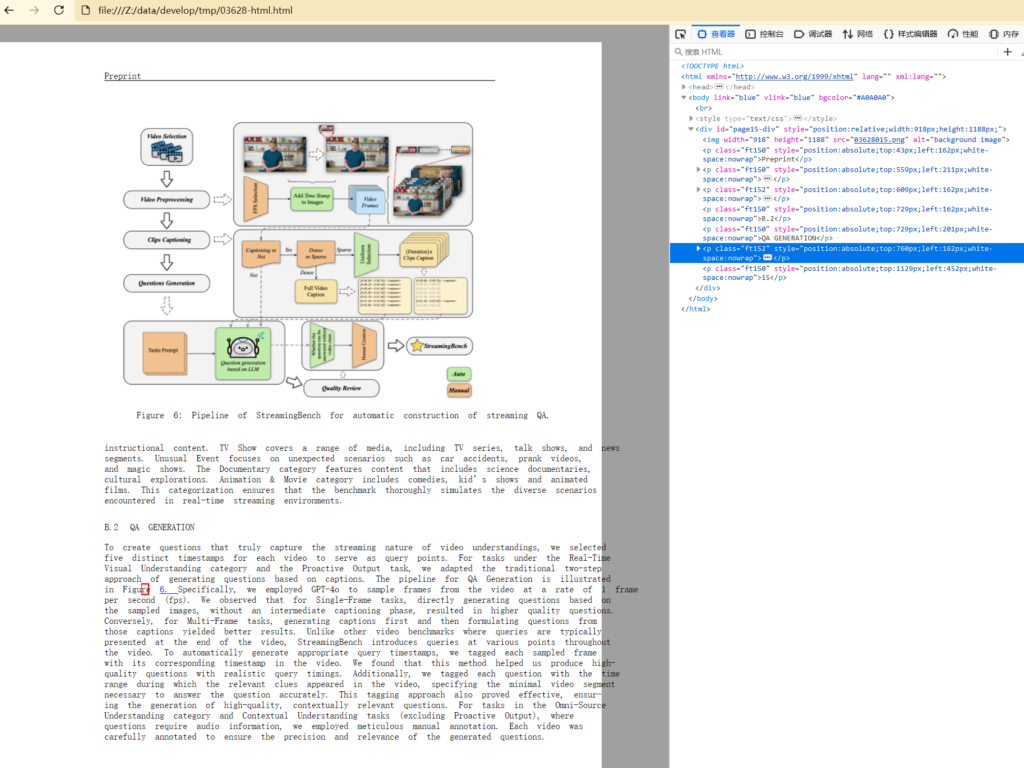
总结
poppler-utils 包含了几个特别有用的工具:PDF转图片、html、文本等。转图片的工具非常实用,支持指定范围切图。转文本、html 的工具对表格处理不够好,还不足以 LLM Ready。这套工具速度特别快,适合作为底层工具构建其他产品。