-
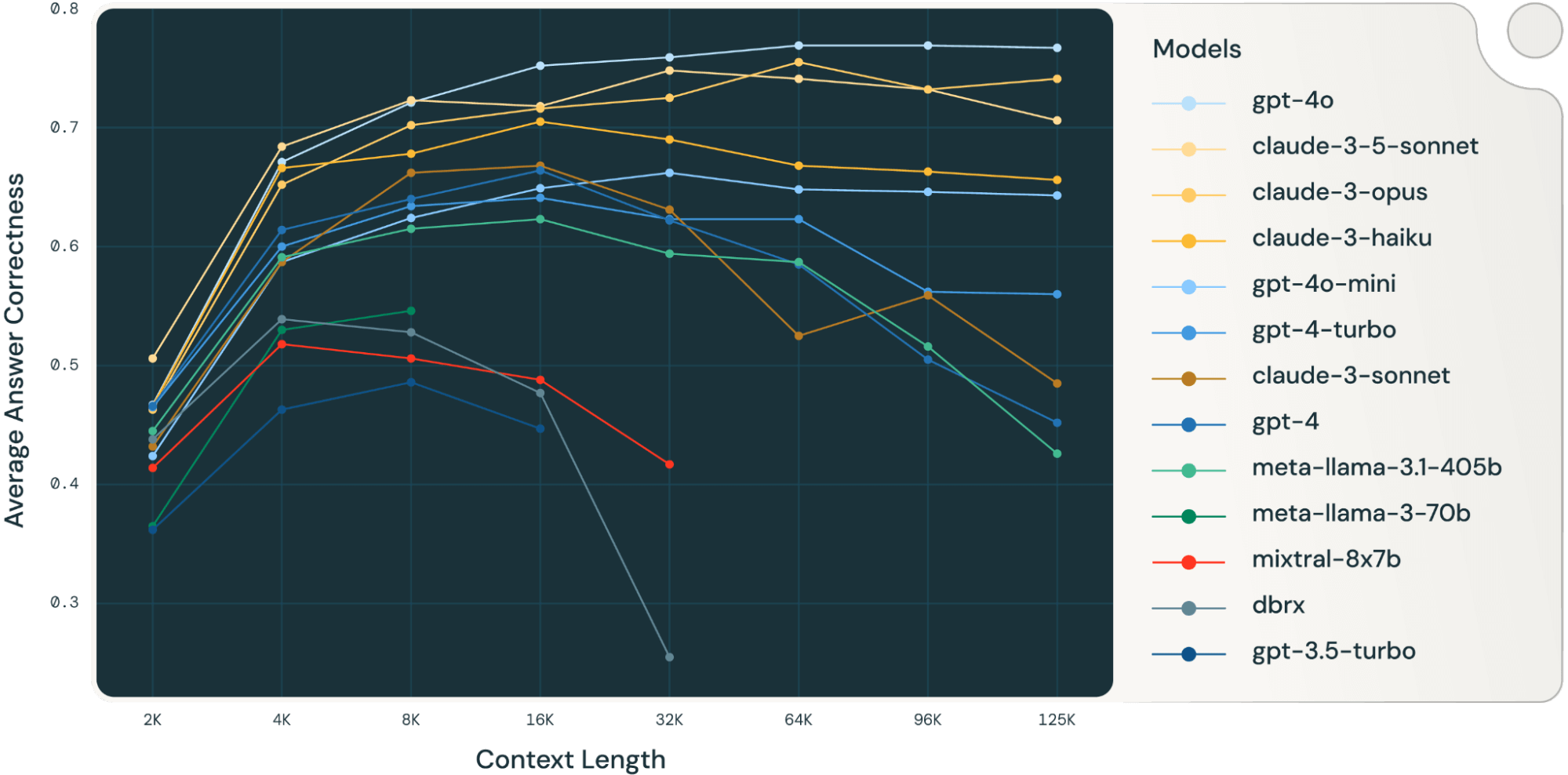
Databrick 对 Long Context RAG 的评测
—
in RAG整体结果 四项评测集的平均正确率 DocQA 的正确率 HotpotQA 的正确率 评测方案 评测方案中的主要设置 retrieval 阶段…
-

大模型超长上下文对 RAG 是降维打击
前言 越来越多的大模型支持了超长的上下文 (context length),例如 Google gemini 一发布就支持 2M。超长上下文的特性大大方便了文档问答应用的开发。而 RAG 作为文档问答的解决方案,是否会被超长上下文…
-
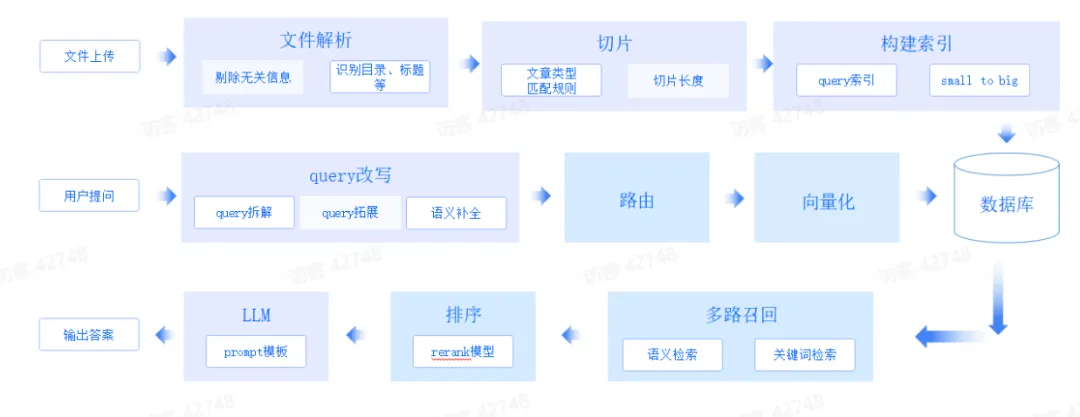
解码RAG:智谱 RAG 技术的探索与实践
产品方案 知识运营层面的产品特性包括:知识类型管理、切片管理、索引管理、数据运营 知识问答过程的产品特性包括:历史消息、输入提示、原文索引、图文混排、原文查看 产品目标用户分类:个人使用、企业对内赋能、企业 toC 提供服务 技术全景图 RAG技术挑战和方案 Embedding 针对前者,我们采用文章结构切片以及…
-
爬取 Coze bot store 的使用量数据
对 Coze 上的 bot 的使用量数据有兴趣,想爬取下来分析热门 bot。虽然之前没做过这类爬虫,但好在有 ChatGPT,直接提问,多提几次,就能写出可用的爬虫了 Coze bot store…