
标题
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
总结
本网页主要介绍了一种名为 IM-RAG 的多轮检索增强生成模型,该模型通过学习内在思维(Inner Monologues)来实现大型语言模型(LLMs)与信息检索(IR)系统之间的协同工作,以提高问答系统的性能和灵活性。
摘要
IM-RAG 是一个以 LLM 为中心的模型,旨在通过学习内在思维来实现多轮检索增强生成。该模型由四个主要组件构成:理论者(Reasoner)、检索者(Retriever)、精炼者(Refiner)和进度跟踪器(Progress Tracker)。理论者负责核心推理,能够根据对话上下文自动切换角色,作为提问者提出查询以获取更多相关文档,或作为回答者根据多轮对话提供最终答案。精炼者的作用是改善检索者的输出,使其更适合 LLM 的需求,而进度跟踪器则通过强化学习提供奖励信号,指导 IM-RAG 的训练过程。实验结果表明,IM-RAG 在 HotPotQA 数据集上实现了最先进的性能,同时提供了高度的灵活性和解释性。
WHY
有两种典型的范式来改进 RAG 系统:联合训练方法与分别训练不同的组件。
第一种范式涉及对LLM和检索器进行知识密集型任务的联合训练,从而增强语言模型的检索能力。然而,它缺乏可解释性,因为 LLM 和检索器之间的通信依赖于复杂的深度学习梯度传播以及 IR 嵌入模型和 LLM 之间的交叉注意力。 此外,这种训练方法的计算成本非常高,并且随着 LLM 的变化或学习,重新训练检索器的语义嵌入非常困难或昂贵。
第二种范式分别改进了 LLM 和/或 IR 引擎。该范式中的大多数先前工作都集中在改进LLM(以LLM为中心)上,通过提示或微调LLM参数[19,29,33]。基于提示的方法提供了简单性和灵活性,而不会产生额外的培训成本,并允许通过 API 调用集成黑盒 LLM 和搜索引擎。但是,它缺乏整个系统的端到端优化。相比之下,基于训练的方法收集和利用 LLM 和 IR 模块之间的人工注释交互记录,然后使用它们来监督 LLM 学习如何更好地利用 IR 模块并与之交互。尽管这种方法在简单的基于图像到文本检索的视觉问答方面显示出比基于提示的方法更好的性能。它需要大量标记的训练数据以及大量的训练成本。对于需要多步骤推理和多轮检索的复杂问题,使用人工标记的多轮搜索记录的训练数据收集成本可能很高,而且其方法的有效性尚不清楚。在这项工作中,我们主要关注改进以 LLM 为中心的范式,考虑其性能、灵活性和可解释性。
最近,IMMO[52]训练了LLM和视觉语言模式,使其具有内心独白(即问答(QA)对话),他们的结果表明,学习的IM可以进行明确的多步骤推理,在复杂的视觉问答问题上表现良好,同时可解释
我们总结了我们的贡献如下:
- 受 IMMO 的启发,我们引入了一种新方法 IM-RAG,它通过学习 IM 将 LLM 和 IR 模块连接起来,以实现上下文感知的多轮 RAG。IM 学习过程可以通过 RL 进行优化,而无需中间人工注释。学习过程使 RAG 系统的关键组件(查询生成、结果排名、答案生成等)能够被训练以匹配其他组件的能力。因此,整个RAG系统得到了优化。
- 我们的工作提供了一种解决方案,可以灵活地采用具有不同功能的 IR 模块和 LLM,以及多轮检索的可解释性。
- 我们在 HotPotQA 数据集 [54] 上证明了我们的方法的有效性,HotPotQA 数据集是一个流行的知识密集型多跳问答数据集,我们的方法实现了 SOTA 性能。
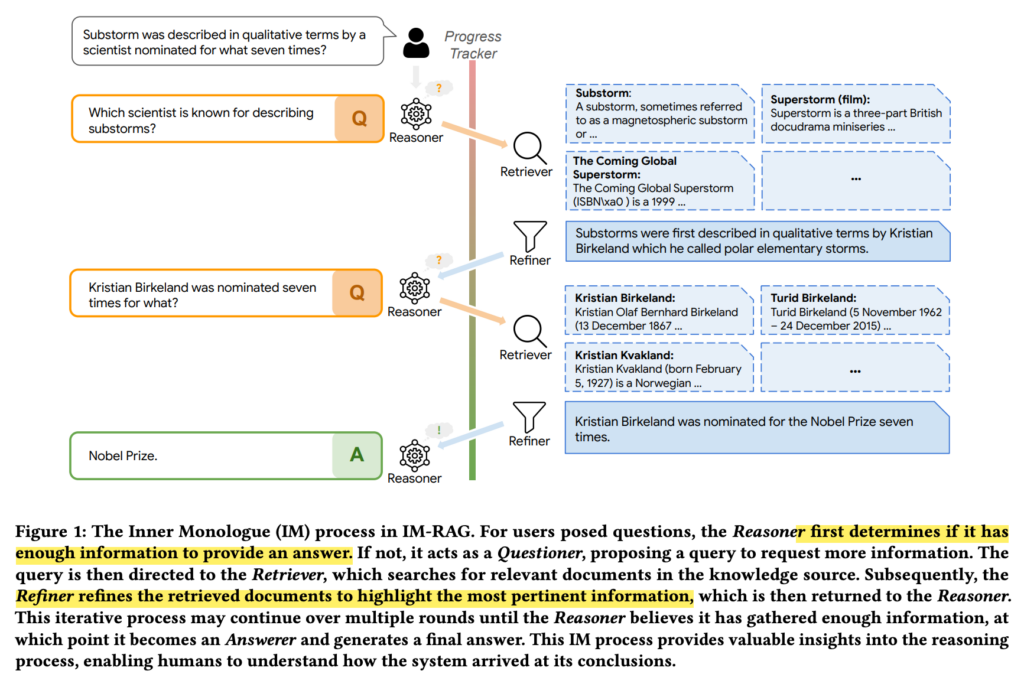
How
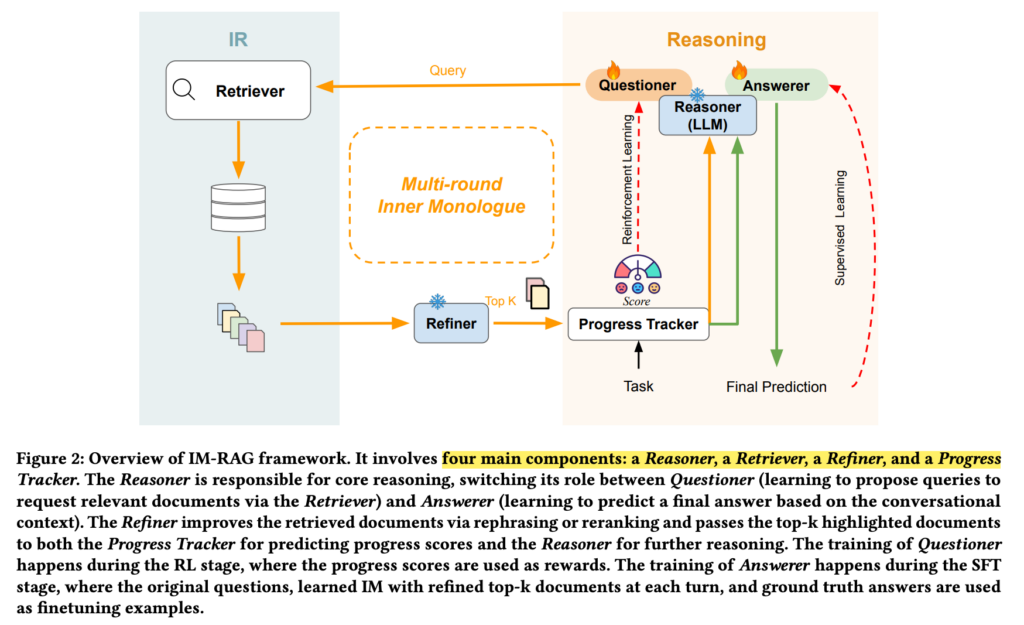
IM-RAG 框架包含 4 个组件:Reasoner、Retriever、Refiner、Progress tracker:
- Reasoner:推理。如图 2 所示,Reasoner 是 IM-RAG 框架中的核心推理组件,具有两个关键职责:(1) 提问:精心设计搜索查询以通过 IR 迭代获取相关文档;(2) 回答:根据推理者和猎犬之间的多轮互动(即 IM-RAG 中的内心独白)为初始问题提供最终答案。对于这两项职责,我们引入了两个不同的参数高效适配器,以在学习过程中专门化每种功能。具体来说,我们在同一个基础 LLM 中添加了两个 LoRA [11] 适配器,即 Questioner 和 Answerer。我们首先通过强化学习通过与猎犬的多轮 IM 来训练提问者。在这个RL阶段,提问者学习如何将一个复杂的任务(例如,一个需要多步骤检索和推理的问题)分解成一系列更简单的子查询。子查询依赖于先前的通信上下文,其中可以包括子查询和上一步中检索到的文档,以及原始问题。然后,我们通过监督微调 (SFT) 训练回答者直接回答原始问题。在 SFT 阶段,应答者利用从 RL 阶段学到的 IM 并提供正确答案。两个适配器的详细训练策略分别在第 3.2.5 节和第 3.2.6 节中说明。
- Retriever:检索。IM-RAG 中 Retriever 组件的目的是在 IM 过程中从 Reasoner 中准确检索给定的搜索查询相关文档。Retriever 的特定架构及其知识资源可以根据各种任务或数据集灵活使用。从概念上讲,大多数现有的搜索引擎、密集检索器或匹配算法都可以作为推理器直接采用到 IM-RAG 框架中。
- Refiner:打磨。如图 2 所示,我们在 IM-RAG 中引入了一个 Refiner 组件,以增强内心独白过程,尤其是 Reasoner 和 Retriever 之间的多轮对话。精炼器用作猎犬输出的后处理器。它的引入有两个主要动机:首先,各种 IR 模块的输出在格式和长度上有所不同,这可能不适合作为 LLM 的上下文提示。Refiner 通过将这些输出改写和标准化为简洁、格式良好的段落来解决这个问题。其次,不同红外模块的不同功能可能导致未过滤或未排序的结果,这可能会限制其实用性。精简程序通过重新排序和过滤来改进这些结果,确保只有重要信息突出。从本质上讲,Refiner 为 IR 模块的选择提供了灵活性,并确保它们与 Reasoner 的兼容性,有效地弥合了 Retriever 和 Reasoner 之间的差距并简化了 IM 流程。
- Progress tracker:进度跟踪器。当搜索空间巨大时,PPO等RL算法本身就受到优化效率低下的困扰[36]。缓解这些低效率的一种方法是在多轮过程中提供精心设计的中间步骤奖励[21,45]。因此,我们在 IM-RAG 中引入了一个进度跟踪器组件,以根据每个回合的检索进度提供奖励分数。当累积分数超过一定阈值时,表明推理者已经获得了足够的信息,并且应该。在实践中,进度跟踪器的评分设计可以灵活,因不同的任务、检索器和数据集而异。这种灵活性可能包括神经奖励模型[30]或离散奖励函数[52]。在IM-RAG中,我们引入了一种基于余弦相似度的软距离评分设计,该设计在保持简单性的同时提供了强大的奖励信号
- Questioner training:
- Answerer training:
在之前的工作[9,43,52]的基础上,Questioner的RL由Transformers Reinforcement-Learning(TRL)库[46]支持,Answerer的SFT由HuggingFace指令微调管道[51]支持。所有超参数都遵循 StackLLaMA [2] 和 Alpaca [43] 的默认设置。借助参数高效微调 (PEFT) [26] 支持,在 4 NVIDIA A100 GPU 环境下,提问者 (RL) 和应答者 (SFT) 分别接受 6 个和 10 个周期的训练。指令提示是从以前的作品[43,52]提供的模板修改而来的。
效果
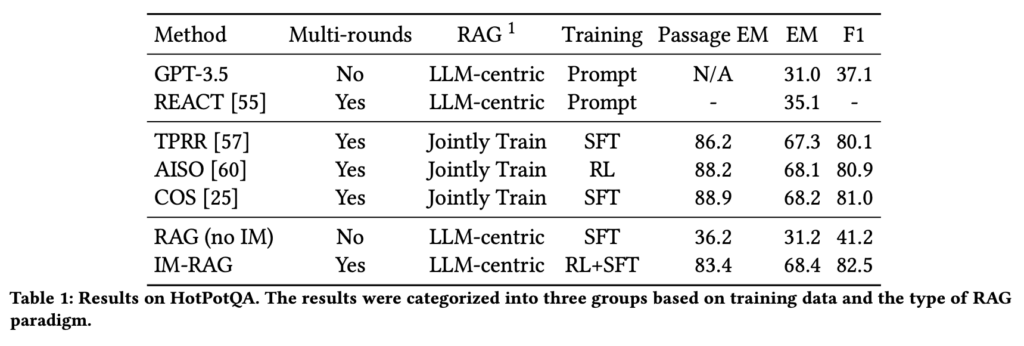
相关信息
DPRR 是什么
DPRR(Dense Passage Retrieval for Re-ranking)是一个在信息检索(IR)领域中用于文档检索和重排序的模型。它结合了两个主要的技术:Dense Passage Retrieval(DPR)和 Re-ranking。下面是对这两个组件的简要介绍:
- Dense Passage Retrieval(DPR):
- DPR 是一种基于深度学习的检索模型,用于从大型文档集合中检索与给定查询最相关的文档或段落。
- DPR 使用双塔架构,其中一个塔用于编码查询,另一个塔用于编码文档或段落。这两个塔通常是基于变换器(Transformer)的模型,如 BERT。
- 通过这种方式,查询和文档被转换为稠密的向量表示,然后通过余弦相似性或其他相似度度量来匹配,以便快速检索最相关的文档。
- Re-ranking:
- 重排序是在初始检索结果的基础上进一步调整文档顺序,以提高检索的准确性和相关性。
- 通常,重排序会使用更复杂的模型来再次评估检索到的文档的相关性,并根据这些评估调整其顺序。
- 重排序模型可能会考虑更多的上下文信息,甚至可以是交互式的,即在查询和文档之间进行交互式推理,以更准确地确定它们之间的相关性。
将这两者结合起来,DPRR 可以在初始的粗略检索阶段使用 DPR 快速检索相关文档,然后在后续的精细化排序阶段使用重排序模型对这些文档进行再排序,以提高最终检索结果的质量。这种方法在处理复杂的问答任务时特别有用,尤其是在需要从大量文本中精确检索信息的情况下。
在 IM-RAG 框架中,DPRR 可以作为检索者(Retriever)模块的一部分,负责从给定的文档库中检索与查询最相关的文档,并通过精炼者(Refiner)进行后处理,以便更好地与理论者(Reasoner)模块协同工作,进而提高整个系统的问答性能。
AISO 是什么
AISO(Action-aware Iterative Search and Optimization)是一个在信息检索和问答系统中应用的框架,它旨在通过迭代搜索和优化来提高检索增强生成(RAG)系统的性能。AISO 的核心思想是将问题解决过程视为一个部分可观测的马尔可夫决策过程(Partially Observable Markov Decision Process, POMDP)。在这个过程中,系统通过迭代地执行动作(例如,提出查询、检索文档、生成答案等)来逐步收集信息并解决问题。
AISO 的主要特点和组件包括:
- 迭代搜索:AISO 框架中的系统会根据当前的知识状态和问题需求,迭代地提出查询并从外部知识源检索信息。这种迭代搜索的过程类似于人类在解决问题时的思考过程,即通过不断提问和寻找答案来逐步构建解决方案。
- 动作感知:AISO 设计了一系列特定的检索和推理动作,这些动作是针对不同类型的问题和任务定制的。系统能够根据任务的需求选择合适的动作来执行,这使得系统对于不同的检索和推理步骤具有感知性。
- 优化:AISO 使用强化学习(Reinforcement Learning, RL)来优化决策过程。通过奖励机制,系统学习如何选择最有效的动作序列,以最大化最终答案的准确性和相关性。
- 端到端训练:AISO 框架允许端到端的训练,这意味着从检索动作到最终答案的生成过程可以一起训练,以便更好地协同工作。
- 灵活性和可扩展性:由于 AISO 将问题解决过程抽象为一系列动作,因此它可以很容易地适应新的检索环境和不同的知识源,只要相应的动作可以被定义和执行。
在 IM-RAG 的上下文中,AISO 可以被看作是一个与 IM-RAG 类似的方法,它也是为了提高大型语言模型(LLM)在多轮检索增强生成任务中的性能。AISO 通过引入动作感知和迭代搜索机制,使得系统能够更加灵活和精确地执行信息检索和答案生成的任务。然而,与 IM-RAG 相比,AISO 可能更侧重于通过预先定义的检索和推理动作来解决问题,而 IM-RAG 强调通过学习内在思维(Inner Monologues)来实现更自然的问题解决过程。
COS 是什么
COS(Chain of Skills)是一个在信息检索和问答系统中应用的框架,它的核心思想是将复杂的问题解决过程分解为一系列链式的技能(skills)。这些技能代表了特定的信息处理或推理步骤,它们可以是自动执行的,也可以是人类专家执行的。COS 的目标是通过组合这些技能来解决需要多步推理和跨文档跳转的复杂问答任务。
COS 的主要特点和组件包括:
- 技能链:COS 将问题解决过程划分为多个步骤,每个步骤对应一个特定的技能。这些技能可以包括实体链接、查询扩展、文档检索、信息提取等。通过将这些技能链式调用,系统能够逐步构建出问题的答案。
- 模块化设计:每个技能都是模块化的,可以独立开发和优化。这种模块化设计使得系统可以根据任务的需求灵活地添加、替换或更新特定的技能。
- 多任务预训练:COS 通常会通过多任务学习来预训练每个技能模块,以便它们能够更好地处理不同类型的输入和任务。
- 协同工作:技能模块可以协同工作,共同解决问题。例如,一个技能可以检索相关的文档,而另一个技能可以从这些文档中提取关键信息,最终由第三个技能将这些信息合成为答案。
- 灵活性和可扩展性:由于每个技能都是独立的,COS 可以很容易地适应新的任务和领域,只要相应的技能可以被开发和集成。
在 IM-RAG 的上下文中,COS 可以被看作是一个与 IM-RAG 类似的方法,它也是为了提高大型语言模型(LLM)在多轮检索增强生成任务中的性能。COS 通过引入一系列链式的技能来解决问题,使得系统能够执行更复杂的信息检索和答案生成任务。与 IM-RAG 的主要区别在于,COS 更侧重于预先定义和训练一系列专门的技能模块,而 IM-RAG 强调通过学习内在思维(Inner Monologues)来实现更自然的问题解决过程。此外,COS 的设计可能需要更多的领域知识和技能链的精心设计,而 IM-RAG 试图通过强化学习和自然语言理解的能力来自动学习和优化问题解决过程。
Leave a Reply