-
海外 VPS 选购对比
—
in Hacker为什么要海外 VPS 如果你搞 SaaS 出海,做独立开发项目,或者搭建一个 WordPress 博客,不想折腾网站备案这些事情,那就要选择海外 VPS,部署在新加坡、日本、北美等地域,让你的目标用户的访问更顺畅。 或者就是想搭一个代理,用来绕过 ChatGPT…
-
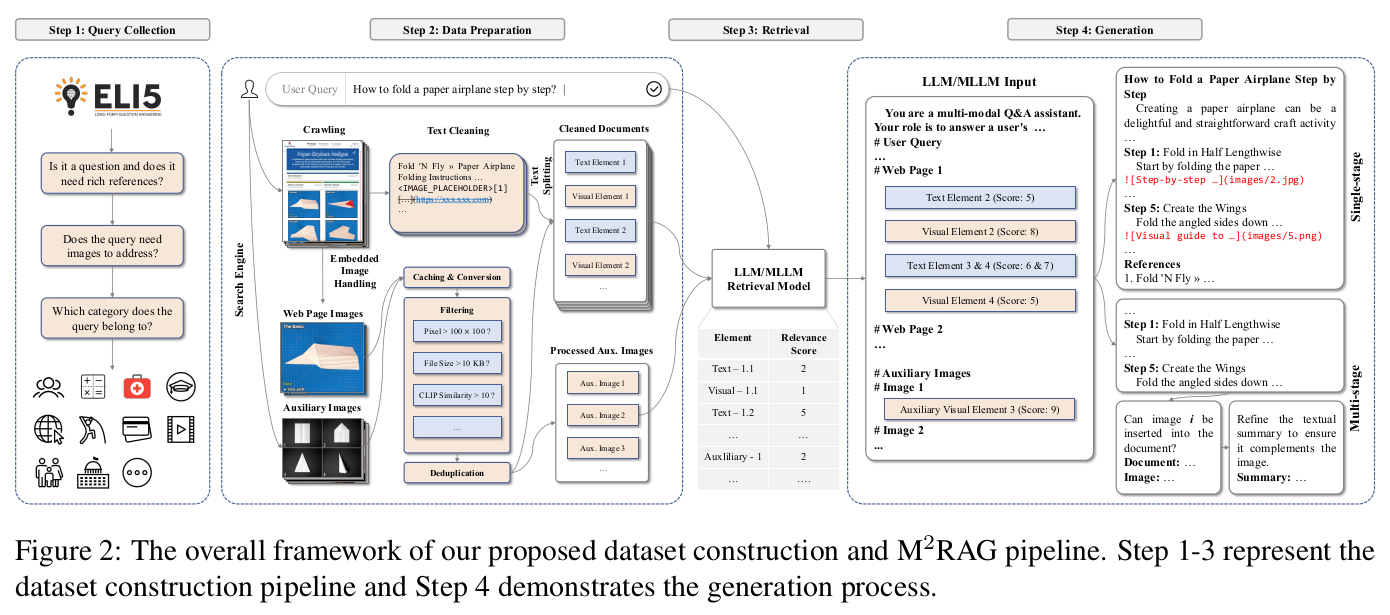
多模态的 RAG:工作流、评测框架和结果
—
in RAG什么是多模态 RAG 真正的多模态 RAG 是指,检索环节支持多模态,生成环节也支持多模态,Multi-modal Retrieval & Multi-modal Generation。多模态(图、文)混排的输出比纯文本(包括Markdown 格式化)的用户体验好很多,图片本身易读、易理解,图片比文字更具象化。…
-

MinerU项目的研究分析
—
in HackerMinerU产品体验 介绍 MinerU 可以把 PDF 转成 markdown/json 文件,支持提取 Table、Image、LaTex 公式,能保证…
-

Poppler: 超强的 PDF 转换和导出工具
—
in Hackerpoppler 是一个用于 PDF 提取、转换、修改等用途的 lib 库,功能强大,速度飞快。 本文里使用 https://arxiv.org/abs/2411.03628 这篇 PDF…
-

怎样做到 LLM Long-Context 越长 RAG 性能越好
总结 这篇来自 Google DeepMind 的论文 “Inference Scaling for Long-Context Retrieval…
-

基于 ColBERT 检索和集成响应评分的语言模型问答
ColBERT Retrieval and Ensemble Response Scoring for Language Model Question…


