
AI 摘要
- 目的: 针对大型语言模型(LLMs)中极长上下文导致的对相关信息关注度下降和答案质量下降的问题,本文重新审视了检索增强生成(RAG)在长上下文答案生成中的有效性。
- 贡献: 本文提出了一种顺序保持的检索增强生成(OP-RAG)机制,通过在原始文本中保持检索到的块的顺序,显著提高了RAG在长上下文问答应用中的性能。
- 实验结果: OP-RAG在答案质量上随着检索块数量的增加形成了一个倒U形曲线,存在最佳点,使得OP-RAG在比长上下文LLMs使用更少令牌的情况下实现更高的答案质量。在En.QA数据集上,使用16K检索令牌的OP-RAG达到了44.43的F1分数,超过了使用128K令牌的长上下文LLMs。
介绍
这篇论文提出了 OP-RAG(Order Preserve RAG)的方案,保留了召回文档 chunk 在原文中的顺序,即可在很短的 RAG context-length 下,比原生 Long-Context LLM 的效果更好。
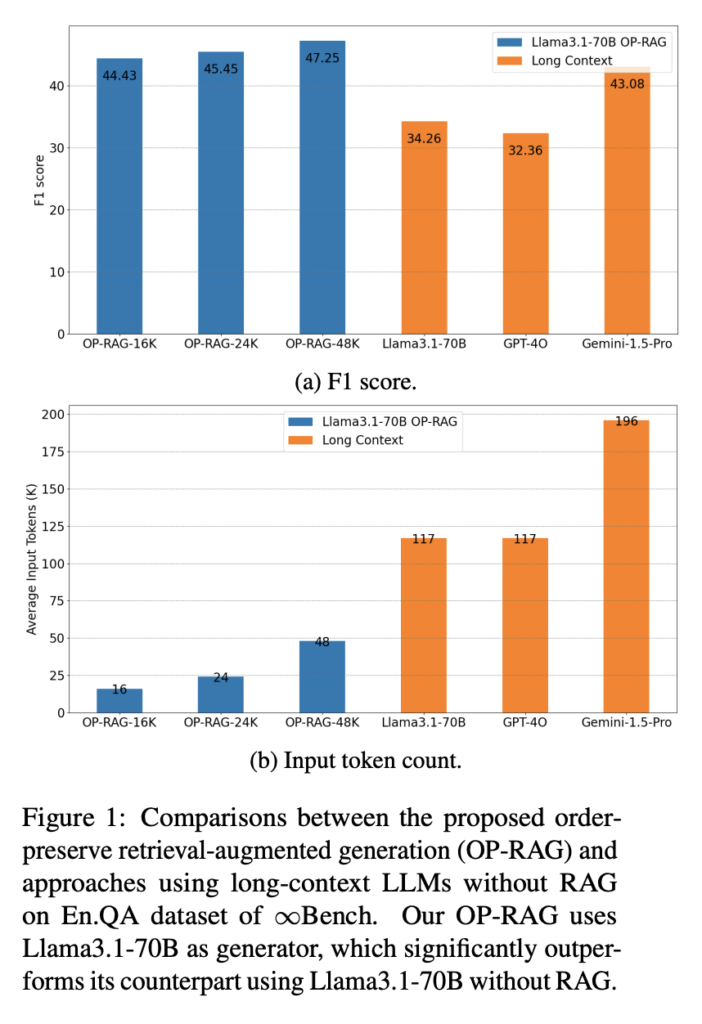
如下图所示,OP-RAG-16k 达到了 44.43 的 F1 得分,相比下原生 Llama3.1-70B-117k 得分 34.26,原生 GPT-4o-117k 得分 32.36,原生 Gemini-1.5-Pro-196K 得分 43.08
方法
OP-RAG 的方法特别简单,就是在召回文档 chunk 后,不是按照常见的问题(Q)和文档(Chunk)的余弦相似性 (cosine similarity)得分降序排序,而是按照 chunk 在原文档中的先后顺序排序。如下图所示。
方案细节:
- Chunk size:128 token
- Embedding model:BGE-large-env1.5

实验数据
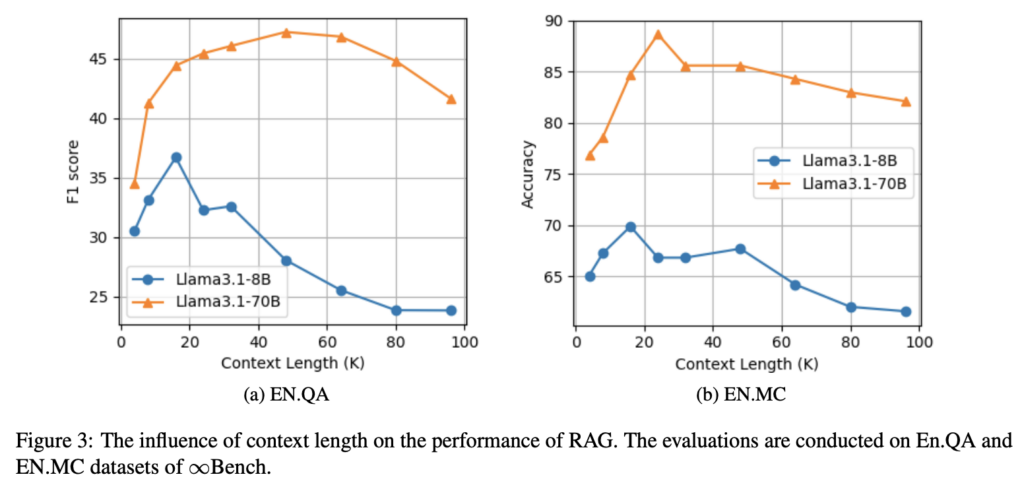
不同模型(Llama3.1-8B & Llama3.1-70B)在不同 Context-Length 下的 RAG 效果对比。
结论:模型在 15k~30k Context-Length 下的 RAG 效果最好
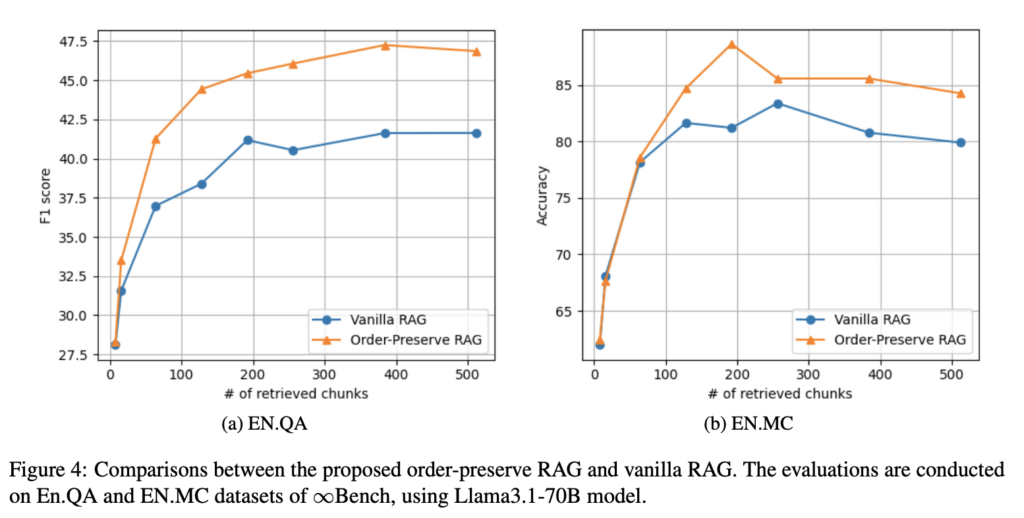
OP-RAG 和常规 RAG 方案在不同 Chunks 数下的效果对比。
结论:OP-RAG 方案总是优于常规 RAG 方案。
论文链接
https://arxiv.org/pdf/2409.01666
Leave a Reply