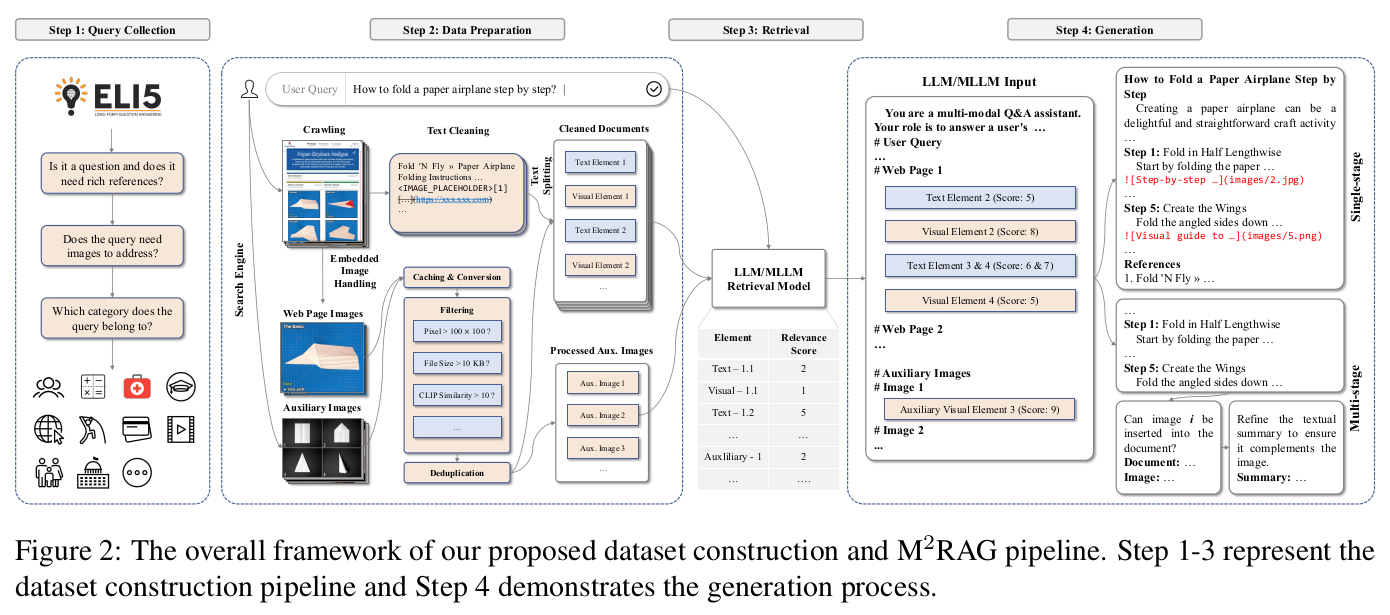
什么是多模态 RAG
真正的多模态 RAG 是指,检索环节支持多模态,生成环节也支持多模态,Multi-modal Retrieval & Multi-modal Generation。多模态(图、文)混排的输出比纯文本(包括Markdown 格式化)的用户体验好很多,图片本身易读、易理解,图片比文字更具象化。
因为模型都能支持 Markdown 格式的输出,因此在输出中增加图片这个工作本身非常简单,直接输出[](https://xxxx.png)这种链接格式即可。
支持多模态的主要工作量在于:图片清洗、图片内容理解、文字&图片的关联。

当前的 AI 搜索产品都支持展示网页中的图片。然而,取决于网页本身的质量、网页作者的意图,页面上的图片可能并非跟网页主题相关,可能会包含宣传图片、广告图片、个人形象等,甚至包含有害的、有恶意的图片。因此清洗图片是很重要的工作。
此外,一张图片也需要跟文本关联起来。图片是为一段文字服务的,一段文字能成为图片的描述。并非所有网页上的图片都会加上 alt 属性、caption 信息便于搜索引擎检索。
上述工作不算复杂,是个工程问题。本文里提到的论文也介绍了作者怎么做。
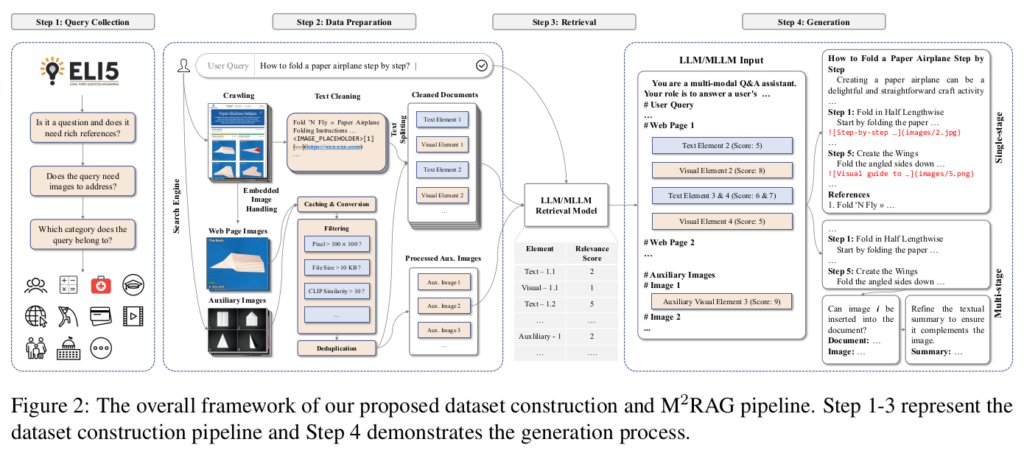
多模态 RAG 工作流
论文里对网页文本和图片的处理办法是:
- 通过 Google Search API 拿到网页后,直接读取网页文本和图片链接。
- 同时也通过 Google Image Search 直接搜索图片。
- 然后剔除低分辨率(size)的图片。
- 基于 CLIP 模型,识别图片、文本的相关性,剔除无关图片。
- 使用去重算法,剔除重复性的图片。
- 把图片通过 Markdown link 的格式嵌入网页文本中

评测方案
在生成阶段,设计了两种方案:单步、多步
- 单步生成:直接在一个 prompt 里包含所有文本和图片URI,让模型直接生成带必要图片 URI 的输出
- 多步生成:先生成纯文本输出;然后切分为不同片段,并让模型判断这个片段是否需要嵌入图片;最后重新合成完整输出
评测框架里包含的评估指标:
- 对文本的指标:Fluency、Relevance、Context Precision、Faithfulness
- 对图片的指标:Image Coherence、Image Helpfulness、Image Reference、Image Recall
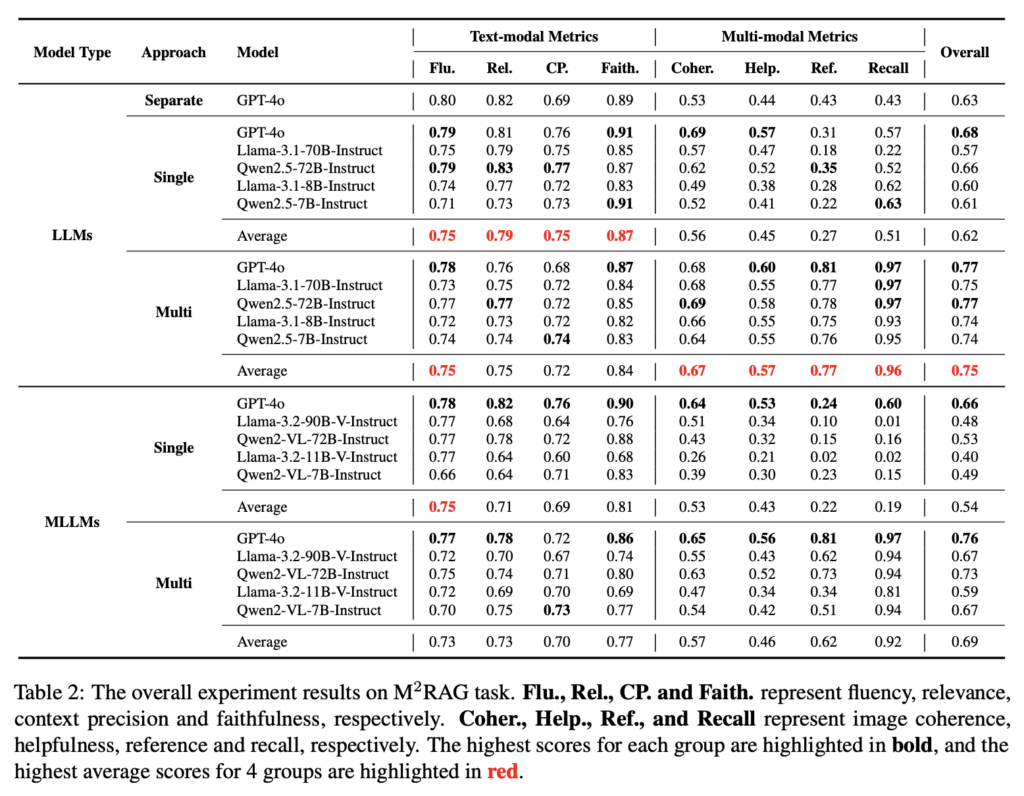
评测结果
解读
- 最佳 LLM base 模型 GPT-4o,开源模型 Qwen2.5-72B-Instruct 稍弱
- Scaling Law 存在:参数越大,模型效果越好
Leave a Reply